
[ 이미지 출처 : https://www.v7labs.com/blog/image-super-resolution-guide ]
Super-Resolution(SR) 이란, 저해상도 이미지(Low resolution, LR) 을 고해상도 이미지(High Resolution, HR) 로 변환하는 과정입니다. 딥러닝이 발전하기 이전부터, Bicubic 과 같은 고전적인 SR 기법들이 존재해왔습니다.
AlexNet(2012) 에 의해 CNN 이 크게 주목받으면서, 기존 고전적인 방법들로 수행해오던 다양한 image processing task 들을 딥러닝에 적용시키고자 하는 시도들이 이어져 왔습니다.
그러한 시도들 중 하나가 바로 Super Resolution 입니다.
그 중에서도 SRCNN (2014) 는 최초로 CNN 기반의 딥러닝 방식으로 Super-Resolution 을 수행한 모델입니다.
( SRCNN paper ↓ )
https://arxiv.org/abs/1501.00092
Image Super-Resolution Using Deep Convolutional Networks
We propose a deep learning method for single image super-resolution (SR). Our method directly learns an end-to-end mapping between the low/high-resolution images. The mapping is represented as a deep convolutional neural network (CNN) that takes the low-re
arxiv.org
본 포스팅에서는 논문에서 설명하는 개념 및 모델의 특징들을 파악해보고
구현된 코드를 분석해보고자 합니다.
SRCNN 및 코드를 공부하고 글을 작성하는데 있어, 아래의 사이트에서 많은 도움을 받았습니다.
아래는 내용 및 코드를 참고한 사이트들의 링크 입니다 !
https://mole-starseeker.tistory.com/82
[논문 리뷰] Super Resolution - SRCNN (ECCV 2014)
다음 학기부터 석사 생활을 시작하게 되었는데, 현재는 연구실에 매일 출근하면서 관심 분야의 논문을 읽어보고 있습니다. 요즘은 Super Resolution(SR), 초해상화에 대해 공부하고 있습니다. 이번 게
mole-starseeker.tistory.com
https://aistudy9314.tistory.com/10
[논문리뷰] SRCNN
오늘은 Image Super Resolution 논문을 하나 공부해보려고 한다. 이전에 접해본 적이 없는 분야라서 틀린 부분이 있거나 추가로 넣어야 하는 정보가 있다면 댓글로 써주길 바란다. 논문의 이름은 Image S
aistudy9314.tistory.com
1. Sparse Coding
SR 을 CNN 기반의 딥러닝에 적용한 최초의 논문이다 보니,
INTRO에서는 기존의 SR 기법과의 연관성을 설명하며, 동작 원리에 대한 대략적인 원리를 설명해주는 듯해 보였습니다.
이 때, 논문에서 설명한 '기존의 SR' 기법이 Sparse coding 입니다.
사실 참고문헌을 찾아가며, 제대로 sparse coding 을 이용한 super-resolution 의 원리에 대해서 이해해보고 싶어 여러 자료들을 찾아보았으나, 이해가 잘 되지 않았습니다.
전체적인 컨셉은 이해하겠으나 디테일한 내용들이 이해가 잘 되지 않은 그런 상태이지만
그래도 이해한 내용을 기반으로 최대한 작성해보도록 하겠습니다.
아래 링크는 SRCNN 논문에 나와있는 sparse coding 관련 refernece 입니다.
https://ieeexplore.ieee.org/abstract/document/4587647
Image super-resolution as sparse representation of raw image patches
This paper addresses the problem of generating a super-resolution (SR) image from a single low-resolution input image. We approach this problem from the perspective of compressed sensing. The low-resolution image is viewed as downsampled version of a high-
ieeexplore.ieee.org
https://ieeexplore.ieee.org/document/5466111
Image Super-Resolution Via Sparse Representation
This paper presents a new approach to single-image superresolution, based upon sparse signal representation. Research on image statistics suggests that image patches can be well-represented as a sparse linear combination of elements from an appropriately c
ieeexplore.ieee.org
Sparse coding 은 Basis function 을 이용합니다.
여기서 Basis function 이란, Fourier transformation 에서의 basis function 와 비슷한 의미라고 이해하였습니다.
[ 출처 : https://slideplayer.com/slide/3361710/ ]
Signal 을 여러 basis function (=sin, cos) 의 linear combination 으로 나타낼 수 있듯이, 이미지 또한 singal 로 볼 수 있으므로
Orinigal iamge X 를 여러 개의 Basis vector (= 작은 patch의 의미)의 linear combination 으로 표현할 수 있지 않을까? 라는 아이디어 입니다.
그리고 이런 patch 의 집합을 Dictionary 라고 합니다. (아래 그림 참고)
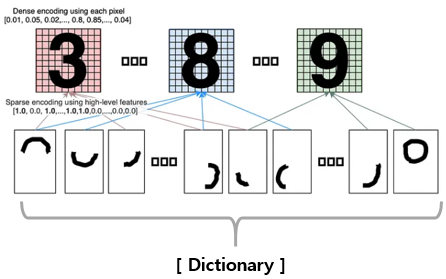
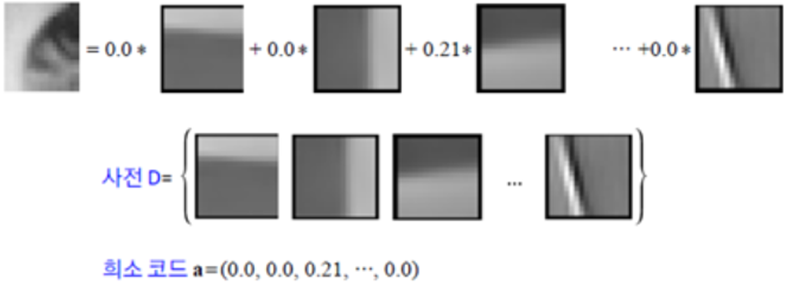
다른 논문에서는 다음과 같이 설명하고 있습니다.

[ 출처 : https://www.sciencedirect.com/science/article/pii/S089360801500043X ]
위 그림과 아래 text에서 하이라이트 표시된 부분을 보시면,
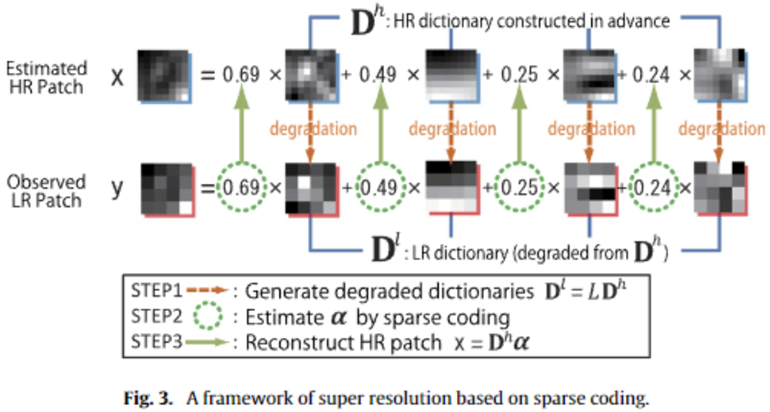
Original image = a·X1 + b·X2 + c·X3 + ··· 로 표현된다고 할 때,
HR resolution image 를 구성하는 패치나, LR resolution image 를 구성하는 패치들이나
coefficient (= a,b,c, ..) 가 동일하다는 겁니다.
즉, ( Low Dictionary와 High Dictionary 두 개 모두를 알고 있다면 )
그리고 (Low dictionary 에 저장된) LR patch 들의 선형결합을 통해 어떠한 Low image 를 조합할 수 있다면,
High dictionary 의 똑같은 위치에 저장된, 즉 LR patch 에 대응되는 HR patch을
LR patch combination 에서 사용했던 coefficient 를 똑같이 적용해서 HR patch 선형결합을 하면 !!
그 때 나오는 이미지가 'image' = HR image 가 된다는 겁니다.
이를 바로 위 text 에서 equation (12) 와 같이 나타냈습니다.
(제가 잘 이해한 건지 모르겠습니다... 혹시 정확하게 아시는 분들은 알려주시면 감사하겠습니다 ㅠㅠ )
그리고 sparse coding 을 푸는 방법은 (Dictionary 를 구성하는 방법) 은 k-SVD 와 같이 잘 알려진 알고리즘으로 풀 수 있다... 라고 하네요.
k-SVD algorithm에 관한 설명은 구글링을 하면 바로 나오기 하는데.. 공부 방향과 너무 멀어지는 것 같아 패스하겠습니다.
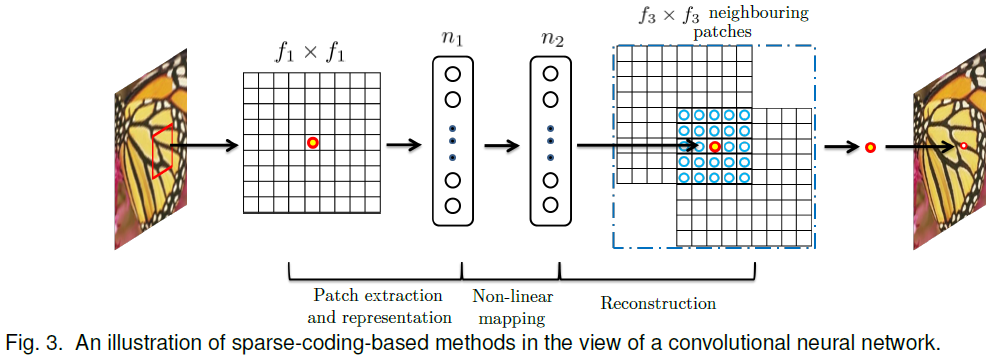
본 논문에서는 위와 같은 figure 를 보여주며 sparse coding 과 SRCNN 과의 상관관계에 대해 열심히 설명하고 있습니다.
솔직히 맞는지는 잘 모르겠는데....
빨간 점은 LR 과 HR 이 서로 대응되는 지점을 의미하는 것 같고,
n1 → n2 는 LR linear combination 에서 계산된 coefficient 들을 HR 차원으로 넘겨주는 것 같고,
f3xf3 neighboring patches 는 HR patch 들의 linear cobination 을 의미하는건가...??
아무튼 결론은 다음과 같습니다.
정확하고 완벽한 원리 이해는 잠시 미뤄두고,
1. Sparse coding 에서도 여러 Patch 들을 사용했었죠.
그런데 Patch extraction 과 같은 과정들은 CNN 에서도 kernel 을 통해 이미 당연하게 하는 과정입니다.
2. LR domain 에서 얻은 coefficient 들을 HR domain 에 mapping 하여 적용할 수 있다고 가정합시다.
이 과정 자체는 단순한 linear operation 으로 여겨질 수 있겠죠?
→ 단순한 linear operation 이라면, 당연히 CNN 으로 Super-Resolution 을 구현할 수 있을 것이다 !
뭐 대충 이런 흐름으로 저는 이해를 했습니다.
더 정확하고 자세한 설명은 아래의 글을 참고하시면 좋을 것 같습니다.
https://aistudy9314.tistory.com/10
[논문리뷰] SRCNN
오늘은 Image Super Resolution 논문을 하나 공부해보려고 한다. 이전에 접해본 적이 없는 분야라서 틀린 부분이 있거나 추가로 넣어야 하는 정보가 있다면 댓글로 써주길 바란다. 논문의 이름은 Image S
aistudy9314.tistory.com
2. Convolutional neural networks for super-resolution
위의 복잡했던 내용들과는 전혀 다르게, SRCNN 의 구조 자체는 매우 단순합니다.
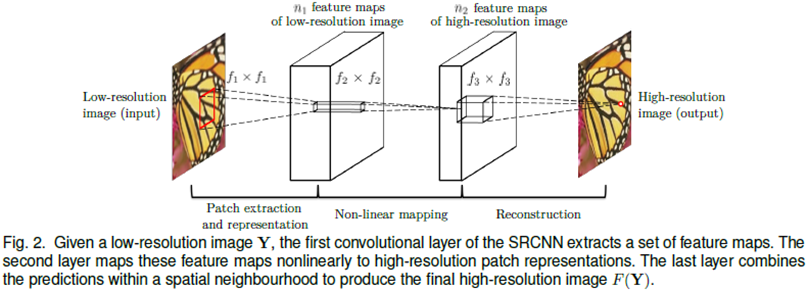
위 그림은 SRCNN 논문에서 가져온 사진입니다.
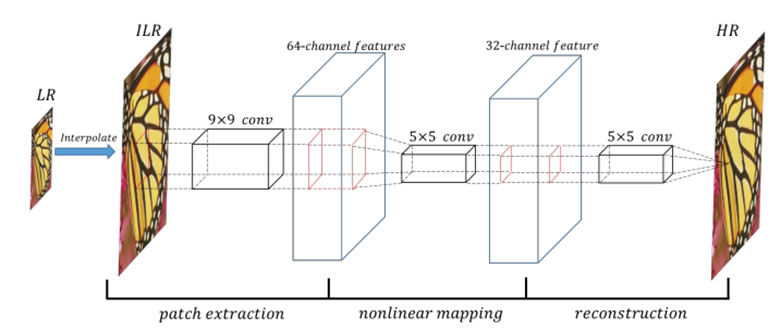
하지만 한 가지 주의해야할 사항이 바로 interpolation 입니다.
아래의 내용을 보시면,

output image의 크기가 input image 보다 당연히 커야하므로, (그래야 super-resolution 이니까)
LR image 자체를 input 으로 바로 넣지 않고 전처리를 하였습니다.
논문에 쓰여져 명시되어 있듯이, 기존에 super-resolution 에 사용되던 bicubic interpolation 이라는 traditional method 를 사용하였습니다.
( Traditional nterpolation method 관련 : https://velog.io/@cha-suyeon/Super-Resolution%EC%9D%98-%EB%8C%80%ED%91%9C%EC%A0%81-%EC%A0%91%EA%B7%BC-%EB%B0%A9%EB%B2%95 )
그래서 위 architecture 사진보다는 아래의 architectue 사진으로 SRCNN 을 보는게 직관적으로 이해하기 편할 것 같습니다. (ILR : Interpolated-Low-Resolution image)
3. Training
Model 에 사용된 loss function 이나 optimizer, 그리고 dataset 전처리 과정 같은 것들은 어차피 model 마다 달라질 뿐더러, 큰 원리 자체는 동일하므로 가볍게 살펴보고 넘어가겠습니다.
Loss function : MSE


- Loss function 으로 MSE 를 사용하였고,
평가지표로 PSNR 을 사용하였습니다.
- PSNR 은 SR 문제에서 많이 사용되는 평가지표로, MSE 와 다음과 같은 관계를 갖습니다.
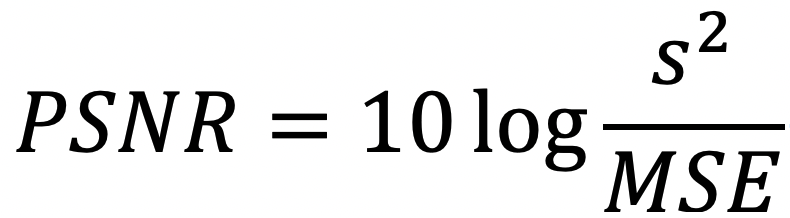
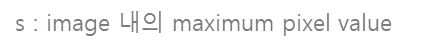
Optimizer : stochastic gradient

Activation Function : ReLU

기타 Datasets 이나 Results 는 굳이 제가 정리까지 하면서 공부할 게 없다고 생각했기에 따로 정리하지 않을 예정이지만,
그래도 Results 정도는 보여드리는 게 좋을 것 같아 논문 figure를 넣어보았습니다.
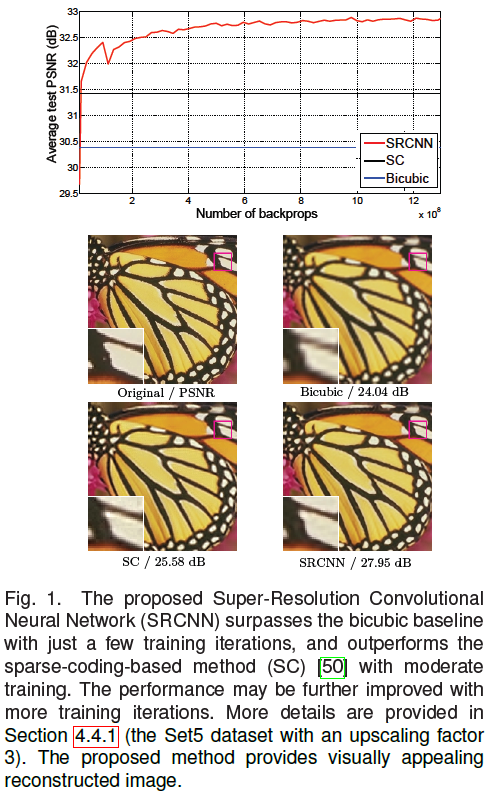
NN은 물론이고 Python 도 처음 사용하는 입장에서 정리해 보았습니다.
찐뉴비 입장에서 하나씩 차근차근 배워 가보자! 라는 의미로 정리하는 내용인지라 설명에 많은 오류가 있을 수 있으니,
지적 및 도움 주시면 언제든지 감사하게 생각하겠습니다...
https://deep-learning-study.tistory.com/688
[논문 구현] PyTorch로 SRCNN(2014) 구현하고 학습하기
안녕하세요, 이번 포스팅에서는 SRCNN을 PyTorch로 구현하고 학습까지 진행한 후에 성능까지 test를 해보겠습니다. 작업 환경은 Google Colab에서 진행했습니다. 논문 리뷰는 아래 포스팅에서 확인하실
deep-learning-study.tistory.com
아래의 code 는 제가 직접 작성한 것이 절대 아닌, 링크 되어있는 위 블로그에서 참고해 가져온 Code 입니다.
제가 직접 작성하여 공유하겠다는 목적이 절대 아니고,
다른 분들께서 구현해주신 code 를 보고 분석해보며 공부하는 입장에서 쓴 글이니 오해 없으시길 바라겠습니다 !
Google colab 에서 구현된 코드 입니다.
from google.colab import drive
drive.mount('srcnn')- PC 환경에서는 사용하고자 하는 Dataset을 적절한 경로에 위치시키면 사용할 수 있듯이,
Colab 은 Google drive 에 dataset을 따로 저장해두어야만 사용할 수 있습니다.
( torchvision.dataset 과 같이 제공되는 데이터셋 or url 링크를 이용하는 경우 ... 등등 제외 )
- 따라서 Colab 에서 나의 Google drive 에 접근할 수 있게끔 하는 코드 입니다.
그리고 이러한 과정을 어렵게 표현하면 'Colab 환경에서 마운트된 Google Drive 에 엑세스 하는 과정' .. 이라고 하네요.
import torch
import matplotlib
import matplotlib.pyplot as plt
import time
import h5py
import srcnn
import torch.optim as optim
import torch.nn as nn
import numpy as np
import math
from torchvision.transforms import ToPILImage
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from torchvision.utils import save_image
import torch.nn as nn
import torch.nn.functional as F
import time
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')- model 을 구현하고 학습시키는 데 필요한 다양한 라이브러리를 불러오기 위한 코드입니다.
' device = torch.device( 'cuda' if torch.cuda.is_available() els 'cpu' ):
- 'torch.device( 'cuda' ~ 는 연산 과정에서 GPU 를 사용하기 위한 모듈입니다.
즉, ' if torch.cuda.is_available() ' : ' 말 그대로 GPU 사용이 가능하면 사용하고,
'else : 'cpu' : GPU 사용이 불가능하면 그냥 CPU 사용해라
라는 의미 입니다.
# DATASET : https://drive.google.com/file/d/1aPxBtvIEMWrLt-awM-0Fko8sJONqOpUx/view
!cd /content
!mkdir data
!unzip /content/srcnn/MyDrive/data/input.zip -d /content/data- LeNet-5 와 AlexNet 은 torchvision.datasets 을 사용하여 각각 MNIST, CIFAR10 을 dataset으로 사용하였는데,
SRCNN 은 직접 다운로드 받은 datasets을 이용하여 학습을 진행하도록 코드가 구현되어 있습니다.
따라서 다운로드 받은 dataset 의 경로를 적절하게 설정해주어서, model 이 정해진 경로로 부터 datasets을 이용할 수 있게끔 설정 해줘야 합니다.
!cd /content
- 작업이 이루어 지는 경로를 /content 로 변경하는 코드입니다.
!mkdir data
- make directory : data 라는 뜻 입니다. data 라는 디렉토리가 생성이 되겠네요.
!unzip /content/~/input.zip -d /content/data
- /content/~/input.zip 를, content/data 라는 경로에 압축해제(unzip) 하라는 코드입니다.
input_h, input_w = 33, 33
out_h, out_w = 33, 33- image 의 size 에 대한 parameter 를 미리 설정해두었습니다.
file = h5py.File('/content/data/train_mscale.h5')
in_train = file['data'][:] # train data
out_train = file['label'][:] # train label
file.close()- 위에서 /content/data 라는 경로에 input.zip 을 압축해제했었죠?
따라서 ' file = h5py.File ~ '은 압축해제된 파일을 열기 위한 코드이며, h5py 는 HDF5파일을 열기 위한 라이브러리 라고 합니다.
- ' in_train = file['data'][:] ' , ' out_train = file['label'][:] '
file 을 통해 열린 train_mscale.h5 를 자세히 살펴보면,
data 라는 데이터셋이 존재할 것이고 또 label 이라는 데이터셋이 존재할 것 입니다.
각각을 in_train, out_train 에 모두( = [:]) 할당하기 위한 코드입니다.
in_train = in_train.astype('float32')
out_train = out_train.astype('float32')' .astype '
- astype 은 데이터타입을 변경하는 코드입니다.
따라서 in_train은 float32 로 데이터타입이 변경되며, float32 는 32비트 부동소수점 데이터타입을 나타냅니다.
자세한 내용은 아래의 링크를 참고하시기 바랍니다.
(x_train, x_val, y_train, y_val) = train_test_split(in_train, out_train, test_size=0.25)- LeNet-5와 AlexNet 에서 사용한 torchvision.dataset 의 MNIST 와 CIFAR10은
' train=True ' or ' train=False ' 를 사용하여 dataset 을 분할하였습니다.
- 위 dataset은 직접 다운로드 받은 dataset이므로, train dat와 val dat 를 직접 나누어 주기 위한 코드입니다.
그리고 그 비율은 0.75 : 0.25 입니다.
class SRCNNDataset(Dataset):
def __init__(self, image_data, labels):
self.image_data = image_data
self.labels = labels
def __len__(self):
return (len(self.image_data))
def __getitem__(self, index):
image = self.image_data[index]
label = self.labels[index]
return (torch.tensor(image, dtype=torch.float),
torch.tensor(label, dtype=torch.float))class SRCNDataset(Dataset) : Dataset 클래스를 상속받은 SRCNNDataset 은
def __init__(self, image_data, labels) :위에서 정의한 image_data, labels 를 매개변수로 받아들입니다.
def __len__(self) :
' self.image_data ' 의 길이(= 샘플 수) 를 얻는 코드입니다.
def __getitem__(self, index) :
- Dataset 클래스를 상속받은 SRCNNDataset 은 self.image_data 와 self.labels 로 부터 [index] 를 받아들인다... 라는 의미인데,
예를 들면, self.image_data 에 100개의 이미지들이 존재할 텐데, index 를 2로 설정하면 뭐 2번 째 샘플 이미지를 불러온 다.. 이런 식으로 이해할 수 있겠습니다.
image 와 label 에 모두 동일한 [index]를 불러오므로, 당연히 이미지에 해당하는 올바른 label값이 얻어지겠죠.
- 그렇게 얻어진 image 와 label 은, torch.tensor 를 이용해서 float 데이터 타입으로 변환됩니다.
train_ds = SRCNNDataset(x_train, y_train)
val_ds = SRCNNDataset(x_val, y_val)
train_dl = DataLoader(train_ds, batch_size=64)
val_dl = DataLoader(val_ds, batch_size=64)' train_ds = SRCNNDataset(x_train, y_train) ' :
- 위에서
' class SRCNDataset(Dataset)
def __init__(self, image_data, labels) '
와 같이 정의하였으므로,
SRCNNDataset (x_train, y_train) 에서 x_train과 y_train 은 각각 image_data와 labels 을 의미하겠죠?
' train_dl = DataLoader( ~ ' :
- dataloader 는 받아온 dataset 을 한꺼번에 넘기는 것이 아니라, mini batch 단위로 쪼개어 나누어서 제공해주는 역할을 합니다.
따라서 ' batch_size = 64 ' 로 넘겨줄 데이터셋의 크기? 개수 를 정의해 줍니다.
이때 넘겨주는 dataset 은 당연히 앞에서 정의한 train_ds 가 되겠습니다. ( ... Dataloader(train_ds, batch_size .... )
for x, y in train_dl:
print(x.shape, y.shape)
break
img = x[0]
target = y[0]
print(img.shape, target.shape)
print(img.dtype)
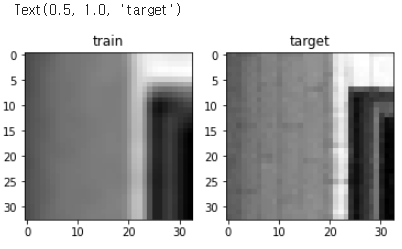
from torchvision.transforms.functional import to_pil_image
plt.figure()
plt.subplot(1,2,1)
plt.imshow(to_pil_image(img), cmap='gray')
plt.title('train')
plt.subplot(1,2,2)
plt.imshow(to_pil_image(target), cmap='gray')
plt.title('target')- 위 과정은 train 과 validation 과는 크게 관계가 없는 코드입니다.
다만 생성된 dataset 을 이미지로 출력하여 확인하기 위한 작업이며, 그 결과는 아래와 같습니다.
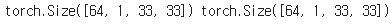
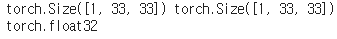
class SRCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 64, 9, padding=2, padding_mode='replicate')
self.conv2 = nn.Conv2d(64, 32, 1, padding=2, padding_mode='replicate')
self.conv3 = nn.Conv2d(32, 1, 5, padding=2, padding_mode='replicate')
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.conv3(x)
return x- AlexNet 과 비교했을 때, 매우 간단한 구조입니다.
다만 convolution layer 마다 kernel size 를 다르게 (9x9, 1x1, 5x5) 설정하였으며,
zero-padding 이 아닌 주변 pixel value 를 복사하는 ' padding_mode = replicate ' 를 사용하였습니다.
def initialize_weights(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
model.apply(initialize_weights);'def initialize_weights(model )
~
if classname = model.__class__.__name__
nn.init.normal_(model. ~ )' :
- initialize_weights 라는 이름에서 알 수 있듯이, 가중치를 초기화하는 함수를 정의합니다.
다양한 model을 공부하다 보면 initialize 라는 용어가 자주 등장하는데 직역하면 '초기화' 입니다.
초기화? 는 뭔가 있던 데이터들은 전부 싹 다 날려버린다 라는 뉘앙스로 인식을 해서 그런지 잘 와닿지가 않더라고요.
그래서 저는 개인적으로 '초기화' 보다는 '초기값 설정' 의 의미로 이해를 하였습니다.
- 어쨌든, 'if classname.find('Conv') ! = -1 ' 란
classname 문자열에서 'Conv' 가 처음으로 나타나게 되는 index 값을 반환한다는 겁니다.
근데 이 때 만약 classname 에 Conv 가 포함되지 않았다? 라고 하면 -1 이 출력이 되는데요,
(바로 위에서 nn.Conv2d~ 할 때 나왔던 Conv)
'! = -1' 의 의미 자체가 '같지 않다' 라는 뜻이라고 합니다.
- 정리하면, 만약 classname 에서 'Conv'를 찾았는데 -1 이 나오지 않았다? ( = 즉 Conv 가 포함된다. )
그렇다면 nn.init.normal 을 실행한다 ! 라는 뜻입니다.
결국 모델의 classname 에 Conv 가 있을 때만, 즉 Conv 에서만 가중치초기화 를 적용하겠다
라는 의미입니다. ( 평균 : 0 / 표준편차 : 0.02 )
' model.apply(initialize_weights) ' :
- 바로 앞에서 정의한 initialize_weight 함수를 model 에 적용하네요.
loss_func = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
def psnr(label, outputs, max_val=1.):
label = label.cpu().detach().numpy()
outputs = outputs.cpu().detach().numpy()
img_diff = outputs - label
rmse = math.sqrt(np.mean((img_diff)**2))
if rmse == 0:
return 100
else:
psnr = 20 * math.log10(max_val/rmse)
return psnr- loss function 과 optimizer 를 적용합니다.
def psnr(label, outputs, max_val=1. ) :
- 위에서 말씀드린 평가지표인 PSNR 을 정의하기 위해 사용된 코드입니다.
label, outputs 를 변수로 받기 때문에 바로 아래줄에서 label 과 outputs 을 정의하네요.
- 여기서 'cpu().detach' 에 대해 설명을 드리자면,
CNN model 은 tensor 형태를 갖는 데이터를 이용해서 backpropagation 을 통해 parameter 를 업데이트 하게 되는데
이 때 연산된 결과들을 어딘가에 기록해둘 것 입니다.
이 때, backpropagation 과정을 중단하고 (학습이 종료되어서) 연산 기록들로 부터 분리된 tensor 를 반환하는 과정이
detach 를 통해 일어나게 됩니다.
- 쉽게 말하면, 계산 다 했으면 결과 내놓으라는.. 그런 코드 입니다.
- 그 아래의 코드는 포스트 위에서 설명드린 PSNR 과 MSE 의 관계를 나타낸 식을 나타낸 코드입니다.
def train(model, data_dl):
model.train()
running_loss = 0.0
running_psnr = 0.0
for ba, data in enumerate(data_dl):
image = data[0].to(device)
label = data[1].to(device)
optimizer.zero_grad()
outputs = model(image)
loss = loss_func(outputs, label)
loss.backward()
optimizer.step()
running_loss += loss.item()
batch_psnr = psnr(label, outputs)
running_psnr += batch_psnr
final_loss = running_loss / len(data_dl.dataset)
final_psnr = running_psnr / int(len(train_ds)/data_dl.batch_size)
return final_loss, final_psnrTrain 함수를 정의하는 과정입니다.
' def train(model, data_dl) :
model.train()
~ '
- 모델을 학습 모드로 전환합니다. 이 때, 초기 loss 와 psnr 은 당연히 0 겠죠.
- 아래 running_loss += loss.item() 에서
.item() 은 pytorch tensor 값을 python 상의 스칼라 값으로 변환하는 것이고,
+= 는 얻어진 스칼라 값을, 매 반복 사이클(epoch)마다 running_loss 에 순차적으로 더한다 라는 뜻입니다.
- 따라서 초기값이 0이므로 학습이 진행될 때 매 epoch마다 running_loss가 결정되겠죠.
' optimizer.zero_grad()
outputs = model(image)
loss = loss_func(outputs, label)
loss.backward()
optimizer.step() ' :
- 이제는 조금 익숙한 코드입니다.
gradient descent 를 이용해서 parameters 를 업데이트한다는 개념은 어떤 모델에서도 동일하므로
다른 model 과 똑같이 사용됩니다.
- 'opt.zero_grad()' 는 optimizer 의 gradient 를 초기화 하는 역할을 합니다.
매번 새로운 batch 가 진행될 때 마다 새로운 gradient 를 계산해야 하니까!
- 'loss.backward' : backpropagation 을 사용해 grdient 를 계산합니다.
- 'opt.step()' : 앞에서 계산한 grdient 들을 사용하여서 optimizer 가 갖는 parameters 를 전부 업데이트 합니다.
def validate(model, data_dl, epoch):
model.eval()
running_loss = 0.0
running_psnr = 0.0
with torch.no_grad():
for ba, data in enumerate(data_dl):
image = data[0].to(device)
label = data[1].to(device)
outputs = model(image)
loss = loss_func(outputs, label)
running_loss += loss.item()
batch_psnr = psnr(label,outputs)
running_psnr += batch_psnr
outputs = outputs.cpu()
save_image(outputs, f'/content/outputs/{epoch}.png')
final_loss = running_loss / len(data_dl.dataset)
final_psnr = running_psnr / int(len(val_ds)/data_dl.batch_size)
return final_loss, final_psnrValidation 함수를 정의하는 과정입니다.
위 Train 함수를 정의하는 코드와 동일합니다.
num_epochs = 100
train_loss, val_loss = [], []
train_psnr, val_psnr = [], []
start = time.time()
for epoch in range(num_epochs):
print(f'Epoch {epoch + 1} of {num_epochs}')
train_epoch_loss, train_epoch_psnr = train(model, train_dl)
val_epoch_loss, val_epoch_psnr = validate(model, val_dl, epoch)
train_loss.append(train_epoch_loss)
train_psnr.append(train_epoch_psnr)
val_loss.append(val_epoch_loss)
val_psnr.append(val_epoch_psnr)
end = time.time()
print(f'Train PSNR: {train_epoch_psnr:.3f}, Val PSNR: {val_epoch_psnr:.3f}, Time: {end-start:.2f} sec')- 정의한 Train + Val 함수를 사용하여,
'for epoch in range(num_epochs)' : num_epochs 수 만큼 반복합니다.
' train_loss, val_loss = [ ], [ ]
~
train_loss.append(train_epoch_loss)' :
- 'trian_loss' 와 'val_loss' 는 각각 리스트이며, 초기에는 비어있는 상태 ( '[ ]' ) 입니다.
- 이 때, 'A.append(B)' 는 B의 값을 A 라는 리스트에 추가할 때 사용됩니다.
즉, 위 코드에서는 train(model, train_dl) 에 의해서 train_epoch_loss 값이 계산되며
계산된 train_epoch_loss 값을 train_loss 라는 리스트에 추가하고 저장하는 것입니다.
for img, label in val_dl:
img = img[0]
label = label[0]
break-
# super-resolution
model.eval()
with torch.no_grad():
img_ = img.unsqueeze(0)
img_ = img_.to(device)
output = model(img_)
output = output.squeeze(0)지금까지 만들고 훈련시킨 model 을 평가하는 단계입니다.
- 이는 학습과정이 아니므로, 'with torch.no_grad()' 를 사용하여 ( = no gradient descent )
단순 input이 학습된 모델을 통과하여 output을 출력하도록 합니다.
- 그리고 model(img_)로 부터 출력된 output은
output.squeeze(0) 에 의해 '첫 번째 차원'이 제거된 상태로 최종 출력되게 됩니다.
그 이유는 print(output.shape) 를 해보면 알 수 있습니다.
- output의 모양은 [batch_size,channel, width, height] 로 되어있는데,
batch는 학습 단계에서만 필요한 것이며 출력된 output 을 보기 위해서는 [channel,width,height]만 필요하기 때문입니다.
따라서 batch_size 에 해당하는 차원을 없애기 위하여 output.squeeze(0) 를 합니다.
(Ex. output.squeeze(1) 을 하면 [batch_size,width,height] 가 됩니다. )
(squeeze, unsqueeze 에 관한 내용은 아래의 링크를 참고하시기 바랍니다. )
https://pytorch.org/docs/stable/generated/torch.squeeze.html
torch.squeeze — PyTorch 2.0 documentation
Shortcuts
pytorch.org
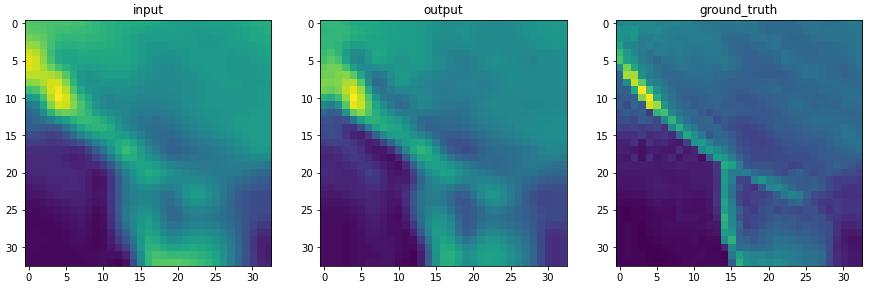
plt.figure(figsize=(15,15))
plt.subplot(1,3,1)
plt.imshow(to_pil_image(img))
plt.title('input')
plt.subplot(1,3,2)
plt.imshow(to_pil_image(output))
plt.title('output')
plt.subplot(1,3,3)
plt.imshow(to_pil_image(label))
plt.title('ground_truth')출력된 input, output, ground_truth 를 plt.figure 를 이용하여 시각화 합니다.
작성자님의 Github 에서 아래와 같은 figure 를 확인하실 수 있었습니다.
https://github.com/Seonghoon-Yu/AI_Paper_Review/blob/master/Super_Resolution/SRCNN(2014).ipynb
GitHub - Seonghoon-Yu/AI_Paper_Review: 까먹으면 다시 보려고 정리합니다.
까먹으면 다시 보려고 정리합니다. Contribute to Seonghoon-Yu/AI_Paper_Review development by creating an account on GitHub.
github.com
'Vision > Machine Learning' 카테고리의 다른 글
| [ML] 초간단 ML History 1 (0) | 2023.06.23 |
|---|---|
| GAN (Generative Adversarial Networks ) (0) | 2023.06.20 |
| Context Encoder (0) | 2023.06.17 |
| AlexNet (0) | 2023.06.15 |
| LeNet-5 (0) | 2023.06.15 |


