------------------ 230608 ---------------- 테스트용 글쓰기 ---------------------
- CNN 에 대한 기초 용어, 개념 등은 시간될 때마다 천천히 추가할 예정
LeNet-5 는CNN 초기 모델로 CNN 을 처음 고안한 Yann LeCun 에 의해 제안된 구조 라고 합니다.
( LeNet-5 paper ↓ )
https://ieeexplore.ieee.org/document/726791
Gradient-based learning applied to document recognition
Multilayer neural networks trained with the back-propagation algorithm constitute the best example of a successful gradient based learning technique. Given an appropriate network architecture, gradient-based learning algorithms can be used to synthesize a
ieeexplore.ieee.org
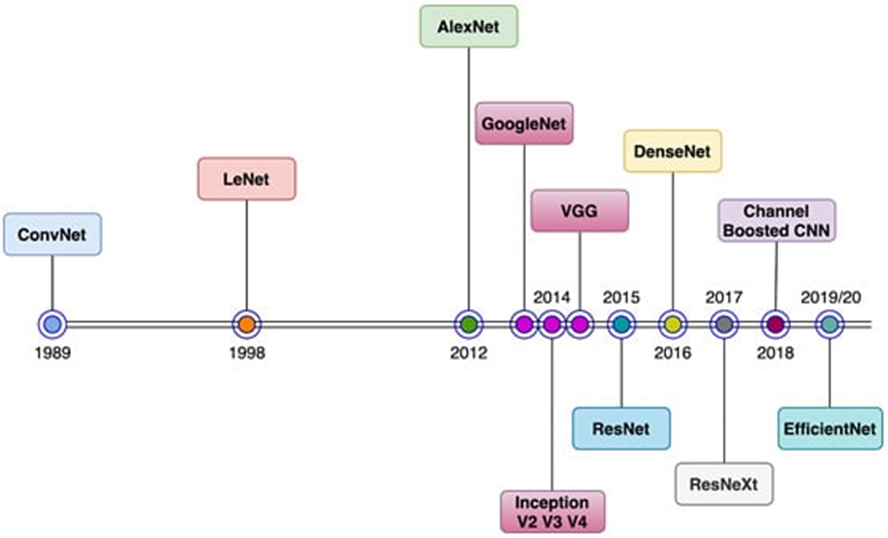
발표 당시 준수한 image classification 에서 준수한 성능을 나타냈고, 지금까지도 많이 사용되는 CNN structure 의 기반을 마련한 중요한 model 로 평가됩니다.
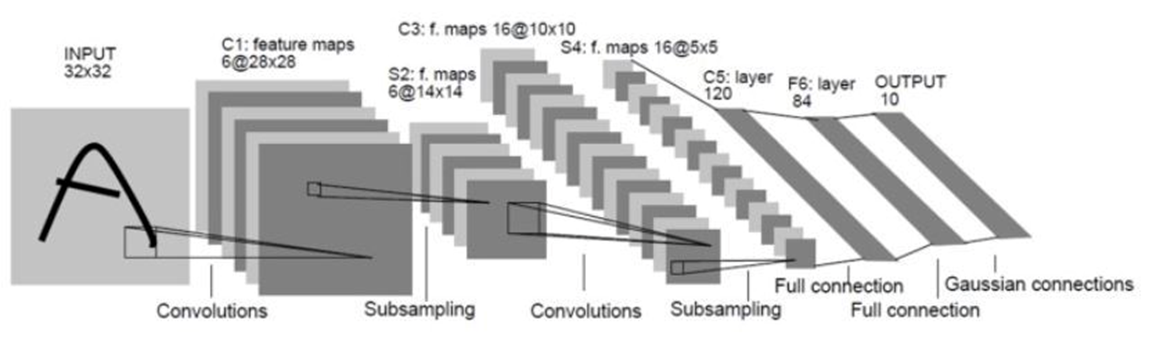
위 그림은 LeNet-5 의 structure 입니다.
그림에서 보시다 시피, Input Layer + output Layer + 3 convolution layer ( = C1, C2, C3 ) + 2 subsampling layer ( = S2, S4 ) + 1 Fully connected layer ( = F6 )
으로 구성되어 있습니다.
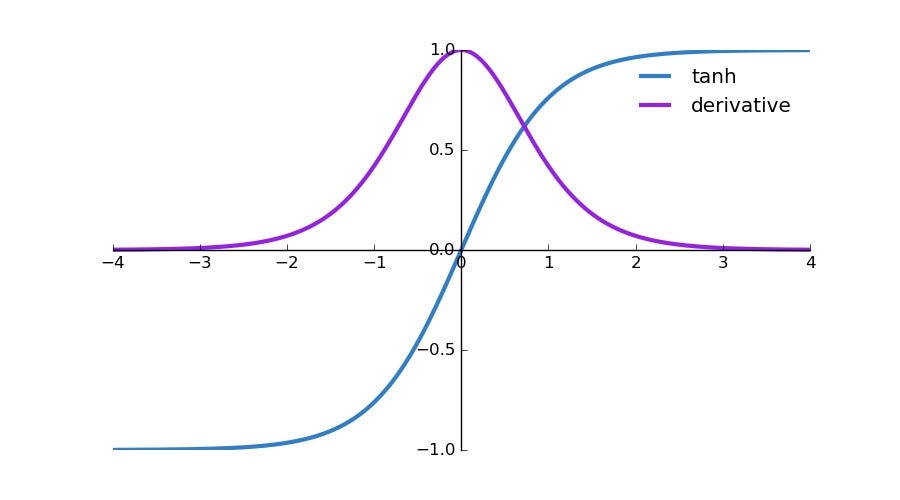
각 레이어마다 activation function 은 tanh 을 사용하였습니다.
1. convolution layer :
- [ C1:feature maps 6@28x28 ] 에서 6은 6개의 채널을 의미 / 28x28 은 말 그대로 feature map의 size 입니다.
- C3, C5 모두 C1와 같은 convolution layer 이지만, 그 중에서도 C3 는 다른 layer 와 다른 독특한 방식을 사용하였습니다.


위 그림은 C3 에서는 6@14x14 Feature maps 에 5x5 kernel 을 사용하여 16@10x10 Feature maps 을 출력하는 과정을 나타냅니다.
X 가 나타내는 것은, feature maps 들 끼리 연결이 되어 있다는 겁니다.
예를 들어, (2,14) 는 X 표시되어 있으므로 S2의 두 번째 feature map 은 C3의 14 번째 feature map과 연결되어 있는 상태입니다.
결국 C1, C5 의 경우 이 전 layer 의 feature maps 들이 그 다음 layer 의 feature maps 들과 전부 연결되어 있지만,
S2 와 C3 사이의 feature maps 들은 각각이 전부 연결되어 있지 않고 듬성듬성(?) 연결된 상태입니다.
그 이유는, 만약 symmetry 한 구조를 갖게 되면 여러 개의 feature maps 을 생성한 의미가 사라지게 되고 결과적으로 정확도가 떨어지기 때문에, symmetry한 구조를 임의로 assymetric 하게 만들어 준다... 라는 식으로 이해했습니다.
논문에서는 아래와 같이 표현하였고요.

C3 뿐만 아니라, LeNet-5 전반적인 strcture 및 원리에 대해 너무 잘 정리해주신 영상이 있어 아래에 링크 남겨 둡니다.
https://www.youtube.com/watch?v=28SQ9wJ74vU
2. subsampling layer :
- subsampling 을 통해 [ C1 : 6@28x28 → S2 : 6@14x14 ] 으로 size 가 변경된 것을 알 수 있습니다.
- 즉 subsampling = pooling 의 역할을 한다고 보시면 됩니다.
- 논문에서는, " ~ subsampling, thereby reducing the resolution of the featuer map and reducing the sensitivity of the output to shifts and distorsions. " 라고 설명되어 있네요.
3. Full connection layer :
- Input image 가 여러 layer 를 거쳐 C5 까지 도달하게 되면 C5에서 120 개의 feature maps 들이 생성 되는데,
이 때 120개의 feature maps 들의 크기는 (1x1)입니다.
( 각 layers 들을 통과할 때마다 feature map 이 어떻게 변화하는 지는
아래의 링크된 사이트에서 자세히 설명이 되어 있습니다.
https://oi.readthedocs.io/en/latest/computer_vision/cnn/lenet.html)
- 120개의 feature maps 들을 84개의 유닛에 연결시킵니다.
4. Output layer :
- Output layer 도 F6와 마찬가지로, F6으로 부터 받은 84개의 유닛이 10개의 유닛으로 연결 됩니다.
따라서 0~9 까지 (총 10개의 label 종류 ) 의 숫자로 이루어진 MNIST image 를 classification 할 수 있게 됩니다.
- Output value 를 출력할 때, 요즘에는 흔히 사용하는 softmax 가 아니라 Euclidean Radial Basis Function 를 사용했다고 합니다.
------------------- 0608 code 작성중 ----------------------
CNN은 물론이고 Python 도 처음 사용하는 입장에서 정리해 보았습니다.
찐뉴비 입장에서 하나씩 차근차근 배워 가보자! 라는 의미로 정리하는 내용인지라 설명에 많은 오류가 있을 수 있으니,
지적 및 도움 주시면 언제든지 감사하게 생각하겠습니다...
https://deep-learning-study.tistory.com/503
https://github.com/Seonghoon-Yu/AI_Paper_Review/blob/master/Classification/LeNet_5(1998).ipynb
[논문 구현] PyTorch로 LeNet-5(1998) 구현하기
안녕하세요! 공부 목적으로 LeNet-5를 파이토치로 구현해보도록 하겠습니다! 논문 리뷰는 여기에서 확인하실 수 있습니다. [논문 리뷰] LeNet-5 (1998), 파이토치로 구현하기 가장 기본적인 CNN 구조인
deep-learning-study.tistory.com
아래의 code 는 제가 직접 작성한 것이 절대 아닌, 링크 되어있는 위 블로그에서 참고해 가져온 Code 입니다.
제가 직접 작성하여 공유하겠다는 목적이 절대 아니고,
다른 분들께서 구현해주신 code 를 보고 분석해보며 공부하는 입장에서 쓴 글이니 오해 없으시길 바라겠습니다 !
Google colab 에서 구현된 코드 입니다.
from google.colab import drive
drive.mount('cookbook')- PC 환경에서는 사용하고자 하는 Dataset을 적절한 경로에 위치시키면 사용할 수 있듯이,
Colab 은 Google drive 에 dataset을 따로 저장해두어야만 사용할 수 있습니다.
( torchvision.dataset 과 같이 제공되는 데이터셋 or url 링크를 이용하는 경우 ... 등등 제외 )
- 따라서 Colab 에서 나의 Google drive 에 접근할 수 있게끔 하는 코드 입니다.
그리고 이러한 과정을 어렵게 표현하면 'Colab 환경에서 마운트된 Google Drive 에 엑세스 하는 과정' .. 이라고 하네요.
import torch
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
print(device)- 필요한 Pytorch 라이브러리 를 불러오기 위함입니다.
'import torch' 에 의해 Pytorch 라이브러리를 현재 pythno 세션에 불러올 수 있다고 하네요.
- torch 를 불러 왔으므로, torch. 을 사용할 수 있습니다. '.' 을 사용함으로써, torch 에서 제공하는 모듈 또는 클래스에 접근할 수 있다고 합니다.
- 'torch.cuda' 는 GPU 를 사용하기 위한 모듈입니다.
즉, 'if torch.cuda.is_available('cuda:0')' : ' 말 그대로 GPU 사용이 가능하면 사용하고,
'else : ~~ torch.device('cpu')' GPU 사용이 불가능하면 그냥 CPU 사용해라 ~
라는 의미 입니다.
from torchvision import transforms
data_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()])'data_transform' :
- 내가 갖고 있는 dataset 이 model의 input 으로 잘 들어갈 수 있게끔 데이터 형태를 변형시키는 작업을 위해
'data_transform' 을 새롭게 정의합니다.
'transforms.Compose' :
-다양한 변환 ( Resize + ToTensor )을 순차적으로 적용하기 위해 '.Compose' 를 사용합니다.
'transforms.Resize' :
- 말 그대로, size 를 다시 정의하는 역할입니다. 여기서는 28x28 size 의 MNIST image 를 32x32로 resize 시킵니다.
'transforms.ToTensor()' :
- PIL 이미지 또는 NumPy 배열을 Pytorch 에서 사용할 수 있도록 텐서 형태로 변환합니다.
- 이렇게 해야만, 일반적인 Pytorch model 에서 input 으로 사용할 수 있다고 합니다.
( 또 PIL 이나 NumPy 는 GPU 로 직접 이동시킬 수 없다고 하네요? 왜??
반면 텐서는 가능하기 때문에 ToTensor 를 사용한다고 이해함..)
from torchvision import datasets
path2data = '/content/data'
train_data = datasets.MNIST(path2data, train=True, download=True, transform=data_transform)
val_data = datasets.MNIST(path2data, train=False, download=True, transform=data_transform)'path2data' :
- 아래에서 train_data, val_data 를 'torchvision.datasets.MNIST' 를 이용해서 받아오게 되는데,
이 때 받아오게 될 경로를 미리 설정해주는 역할을 합니다.
'train_data', 'val_data'
- MNIST dataset 을 직접 다운받아서 google drive 올리지 않더라도,
'torchvision.datasets.~' 을 사용하여 MNIST dataset 을 사용할 수 있습니다.
- 앞에서 설정한 경로 (path2data )를 지정해 주고, download=True 를 통해 다운로드 해줍니다.
- 앞에서 이미 data_transform 을 정의해 주었으므로, 'transform=data_transform' 을 사용하여 MNIST dataset 에 곧바로
적용해 줍니다.
따라서 28x28 MNIST images 는 32x32 Tensor 형태로 train_data와 val_data 에 저장되겠네요.
- train=True 는 당연히 train 으로, train=False 는 validaton 으로 활용되게끔 설정해 줍니다.
from torchvision import utils
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
x_train, y_train = train_data.data, train_data.targets
x_val, y_val = val_data.data, val_data.targets
if len(x_train.shape) == 3:
x_train = x_train.unsqueeze(1)
if len(x_val.shape) == 3:
x_val = x_val.unsqueeze(1)
def show(img):
npimg = img.numpy()
npimg_tr = npimg.transpose((1,2,0))
plt.imshow(npimg_tr, interpolation='nearest')
x_grid = utils.make_grid(x_train[:40], nrow=8, padding=2)
show(x_grid)'x_train, y_train = train_data.data, train_data.targets' :
- train_data 는 이미 MNIST dataset 이었죠. MNIST dataset 에는 이미지의 pixel value 값들 뿐만 아니라, 해당 이미지가
어떤 숫자를 나타내는지 labeling 되어 있습니다.
- 이 때, train_data.data : x_train 은 이미지의 pixel values 를,
train_data.target : y_train 은 해당 이미지의 label 값을 받게 됩니다.
'if len(~) == 3: ~ x_train.unsqueeze(1)'
- x_train.shape 를 사용하면 x_train의 모양이 얻어지는데,
이 때 만약 x_train이 3차원이면 unsqueeze 를 통해 4차원으로 만들어라~ 라는 뜻 입니다.
[ Ex. (batch, height, width) → (batch,height,width) ]
- unsqueeze 라는 개념이 잘 이해가 안 됐습니다.
unsqueeze 자체는 어떤 배열 index에 차원을 추가함으로써 model 의 input 에 맞게끔 데이터 형태를 변환시키기 위한 목적이라는 것은 알겠는데, unsqueeze(1), unsqueeze(2) 의 차이가 머리 속에서 그려지지는 않더라고요.
직관적으로 이해가 안돼서 그림도 찾아봤는데 거기서 거기인 것 같고... 일단은 받아들이고 넘어갔습니다.
'def show(img)' :
- 데이터를 이미지로 보기 위해 show 를 정의합니다.
- Matplotlib 에서 이미지를 표시하기 위해 img.numpy 를 사용한다는 것 외에 별다르게 확인해볼 내용은 없어 보였습니다.
from torch.utils.data import DataLoader
train_dl = DataLoader(train_data, batch_size=32, shuffle=True)
val_dl = DataLoader(val_data, batch_size=32)'DataLoader' :
- dataloader 는 data를 한 번에 넘기는 것이 아니라, mini batch 단위로 나누어서 제공해주는 역할을 합니다.
따라서 batch_size 를 지정해 주어야 하며
- epoch 마다 shuffle 을 함으로써 (데이터를 넘겨줄 때 섞어서 넘겨주는 역할? )
과적합을 줄일 수 있도록 설정할 수 있습니다.
from torch import nn
import torch.nn.functional as F
class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1)
self.conv3 = nn.Conv2d(16, 120, kernel_size=5, stride=1)
self.fc1 = nn.Linear(120, 84)
self.fc2 = nn.Linear(84, 10)
def forward(self, x):
x = F.tanh(self.conv1(x))
x = F.avg_pool2d(x, 2, 2)
x = F.tanh(self.conv2(x))
x = F.avg_pool2d(x, 2, 2)
x = F.tanh(self.conv3(x))
x = x.view(-1, 120)
x = F.tanh(self.fc1(x))
x = self.fc2(x)
return F.softmax(x, dim=1)
model = LeNet_5()
print(model)앞서 설명드린 LeNet-5 의 구조를 위 코드에서 확인할 수 있습니다.
kenerl_size 는 전부 5x5 이고, 각 레이어마다 activation functio 으로 tanh 을 사용하였습니다.
'return F.softmax(x, dim=1)' :
- 편의상 output layer 에 softmax 를 사용하였습니다.
- 'dim = 1' 은 클래스별 확률 값을 나타내기 위한 설정값으로, 클래스 차원에 따라 확률 값을 계산하라 는 의미 입니다.
따라서 input image 의 labe과 일치하는 유닛에서 value (=확률 값)가 가장 높은 output 이 출력됩니다.
'class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()' :
- 사실 아직 Class, __init__(self), super, ... 가 뭔가 똑 부러지게 이해는 되지 않습니다.
단지 이해하지 않아도 쓸 수 있을 뿐더러 그냥 익숙해져서 받아들이기 편해졌을 뿐..
아래의 링크는 제가 이해하는 데 참고한 사이트들 입니다.
파이썬(Python): 클래스(class) 안 def __init__(self): 와 self 등을 제대로 이해하기
"def __init__(self):" 파이썬python을 약간이라도 다루기 시작한 사람이라면 이내 마주치는 구문이다. 개인적으로는 def __init__(self) 구문은 파이썬에서만 사용하는 함수로 안다. 다른 언어에서 본 적이
writingstudio.tistory.com
43. class 정리 - 상속(inheritance)
## 1. 상속(inheritance) 이란? - 클래스에서 상속이란, 물려주는 클래스(Parent Class, Super class)의 내용(속성과 메소드)을 물려받는 클래스…
wikidocs.net
model.to(device)
print(next(model.parameters()).device)바로 앞에서 'model = Lenet_5()' 로 받았으니, model 을 GPU 로 넘기는 과정입니다.
'.to(devcie)' 의 의미는 위에서 정의한 'device' 를 참고하시면 됩니다.
loss_func = nn.CrossEntropyLoss(reduction='sum')
opt = optim.Adam(model.parameters(), lr=0.001)
def get_lr(opt):
for param_group in opt.param_groups:
return param_group['lr']
from torch.optim.lr_scheduler import CosineAnnealingLR
lr_scheduler = CosineAnnealingLR(opt, T_max=2, eta_min=1e-05)loss function과 optimizer 를 정의합니다.
( LeNet-5 의 전체적인 구조를 이해하기 위한 코드 분석이 목적이므로,
실제 논문에서 설정한 값과 완벽하게 일치하지 않아도 신경 쓰지 않았습니다. )
'def get_lr(opt):
for param_group in opt.param_groups:
return param_group['lr']' :
get_lr 을 정의하며, opt 라는 인자를 받습니다.
따라서 opt.param_group 에서 학습률 (learning rate , lr)을 가져올 수 있게 됩니다.
'CosineAnnealingLR ~' :
- Learning Rate 가 cosine 형태로 진동하면서 최적점을 찾아가는 방식입니다.
- T_max : 주기 T의 절반 / eta_min : lr이 갖는 최소값
def loss_batch(loss_func, output, target, opt=None):
loss = loss_func(output, target)
if opt is not None:
opt.zero_grad()
loss.backward()
opt.step()
return loss.item()'opt.zero_grad()
loss.backward()
opt.step()' :
- 이 부분은 Pytorch 를 사용한 다른 model 에서도 똑같이 쓰인다.
왜냐하면 gradient descent 를 이용해서 parameters 를 업데이트한다는 개념은 동일하니까 !
- 'opt.zero_grad()' 는 optimizer 의 gradient 를 초기화 하는 역할을 한다.
매번 새로운 batch 가 진행될 때 마다 새로운 gradient 를 계산해야 하니까!
- 'loss.backward' : backpropagation 을 사용해 grdient 를 계산합니다.
- 'opt.step()' : 앞에서 계산한 grdient 들을 사용하여서 optimizer 가 갖는 parameters 를 전부 업데이트 합니다.
'Vision > Machine Learning' 카테고리의 다른 글
| [ML] 초간단 ML History 1 (1) | 2023.06.23 |
|---|---|
| GAN (Generative Adversarial Networks ) (0) | 2023.06.20 |
| Context Encoder (0) | 2023.06.17 |
| SRCNN ( Super-Resolution CNN ) (1) | 2023.06.16 |
| AlexNet (0) | 2023.06.15 |


