LeNet-5 에 이어서 AlexNet 입니다.
AlexNet이 주목받은 것과 더불어 CNN이 부흥하게 된 것은
2012 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 AlexNet 이 1위를 차지했기 때문이라고 해도 과언이 아닙니다.
[ AlexNet paper ↓↓ ]
ImageNet Classification with Deep Convolutional Neural Networks
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
AlexNet 은 LeNet-5 이후로 약 10년이 넘는 시간동안 발전하지 못했던 CNN 의 부흥을 일으킨 만큼,
그 당시 model의 성능을 획기적으로 높일 수 있는 다양한 방법들을 사용하였습니다.
본 포스팅에서는 논문에서 사용된 '다양한 방법' 들 위주로 간략하게 설명하고,
코드를 분석해보고자 합니다.
AlexNet 및 코드를 공부하고 글을 작성하는데 있어, 아래의 유튜브, 블로그 및 github에서 많은 도움을 받았습니다.
아래는 내용 및 코드를 참고한 사이트들의 링크 입니다 !
https://www.youtube.com/watch?v=40Gdctb55BY
https://devlee247.com/papers/2022-06-13-alexnet/
[논문 리뷰 및 구현] AlexNet(2012) 리뷰 및 파이토치(PyTorch) 구현
AlexNet : ImageNet Classification with Deep Convolutional Neural Networks 파이토치(PyTorch) 구현한 피드입니다.
devlee247.com
https://github.com/Devlee247/PyTorch-Implementations/blob/master/CNN/AlexNet.ipynb
GitHub - Devlee247/PyTorch-Implementations: A simple PyTorch implementation of various deep learning models.
A simple PyTorch implementation of various deep learning models. - GitHub - Devlee247/PyTorch-Implementations: A simple PyTorch implementation of various deep learning models.
github.com

- 위의 그림과 같이 AlexNet 은 크게
[ 5개의 Convolution layers + 3 개의 Fully-connected layers ] 로 이루어져 있습니다.
- LeNet-5 은 Activation function으로 tanh 을 사용하였지만,
AlexNet 은 activation function 으로 ReLU 를 사용하였고, pooling 은 Max pooling 을 사용하였습니다.
본격적으로 AlexNet 에서 제안한 획기적인 방법이 어떤 것들이 있었는 지 적어보겠습니다.
1. ReLU Nonlinearity
[ 출처 : https://dergipark.org.tr/en/download/article-file/2034482 ]
- CNN 은 backpropagation 에 의해 파라미터가 업데이트 됩니다.
이 때, chain rule + derivative 를 사용하여 파라미터를 업데이트 시키죠.
( 이에 대한, 자세한 설명은 아래의 링크를 참고하시기 바랍니다.
https://ratsgo.github.io/deep%20learning/2017/04/05/CNNbackprop/)
- 하지만 LeNet-5 에서 사용한 tanh 를 자세히 보시면,
input 으로 어떤 값이 들어오더라도 output 의 범위는 [-1,1] 로 한정되어 있습니다.
따라서 derivative 값이 1보다 작은 값들이 계속해서 곱해지기 때문에,
파라미터를 업데이트 하는 과정에서 점점 작은 값들이 곱해지게 되겠죠.
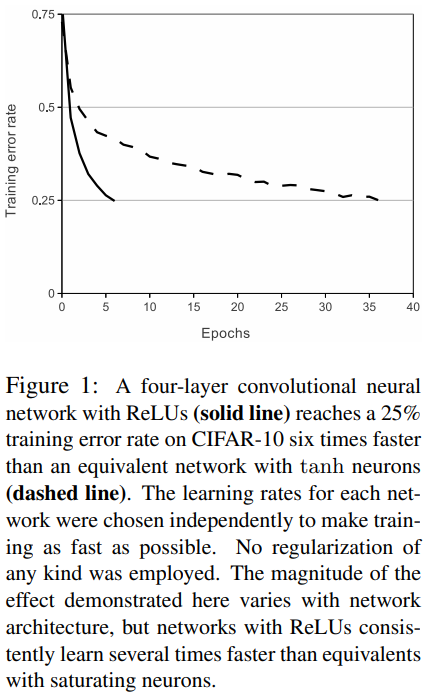
이는 곧, Training error rate 가 느리게 수렴하게 되는 원인이 됩니다.
- 하지만 AlexNet은 ReLU 를 사용함으로써, 수렴 속도를 높이게 됩니다.
논문에서는 tanh 와 같은 함수를 Saturating function, ReLU 와 같은 함수를 non-saturating function 이라고 했습니다.
즉, tanh 는 [-1,1] 로 bounded 되어 있기 때문에 gradient 값이 완만 ( < 1) 해질 수 밖에 없는 반면에,
ReLU 는 무한대로 발산하여 non-saturate 하기 때문에, gradient 값으로 0 or 1 만을 갖게 되어 이러한 문제를 해결할 수 있 었다고 주장합니다.
논문에서는 아래와 같이 간단하게 표현되었습니다.

2. Training on Multiple GPUs
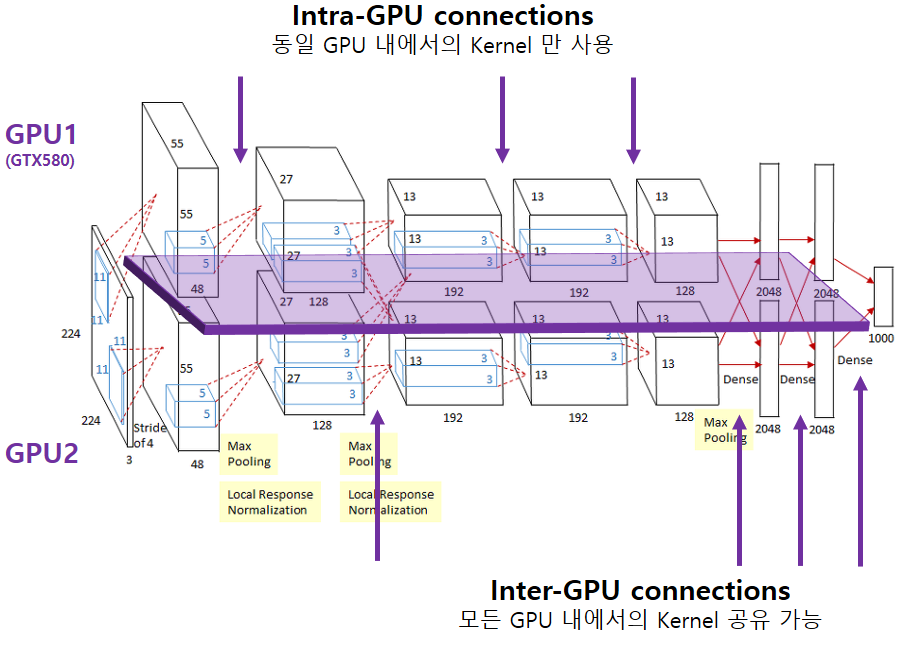
- AlexNet 은 2012 년 발표된 모델로 이 당시만 해도 GPU 의 성능이 지금과 같이 좋지 않았었기 때문에,
두 개의 GPU 를 병렬로 연결하여 사용하였다고 합니다.
( 논문에서는 ' ~ novel or unusual features of out network's architecture.' 라고 주장하는 주요 특징 중 하나이지만,
GPU 성능이 좋은 최근에는 적용할 필요성이 적은 방법이기 때문에 간단하게 넘어가겠습니다. )
- 서로 다른 두 개의 GPU 에서 연산된 결과들이 output 에서는 하나로 합쳐져야 합니다.
따라서, 서로 다른 GPU 에서 추출된 각각의 Features이 독립적으로 학습되는 것을 방지하고자
Inter-GPU connections 를 사용하였습니다.
- Inter-GPU connection 은 말 그대로, 중간중간마다 서로 다른 GPU에서 연산한 결과를 공유하여,
섞인 Feature map 들을 전체적으로 학습시키기 위한 목적으로 사용됩니다.
논문에서는 아래와 같이 표현하였습니다.

3. Local Response Normalization (LRN)
( 현재는 LRN 이 아닌 주로 Batch normalization 이라는 개념을 사용한다고 합니다.
따라서 간략하게 정리한 후 넘어가도록 하겠습니다. )
- 위에서 AlexNet 은 activation function 으로 ReLU 를 사용하였습니다.
하지만 ReLU 는 매우 큰 값이 입력되었을 때, 그 값이 그대로 출력이 되는 구조입니다.
- 이러한 '지역적인 (local) 현상을 방지하기 위하여
여러 Filter들 사이의 output 을 정규화하는 것이 LRN 입니다 .
( 한 마디로, delta function 과 같이 갑자기 특정 구간에서 확 튀어버리는 값을 제어하기 위함.. 이라고 이해하였습니다. )
논문에서는 아래와 같이 표현되어 있습니다.
수식을 보시면 어떤 개념인지 대략적으로 이해가 되실 겁니다.

LRN에 대해 더 자세한 설명은 아래의 링크에서 매우 친절하고 자세하게 설명이 되어있습니다.
참고로 LRN 뿐만 아니라 다른 내용들도 너무 잘 설명해주셨으니, 공부하시는 입장이라면 꼭 한 번 읽어보시면 좋을 듯 합니다 !
https://daeun-computer-uneasy.tistory.com/33
[CV] AlexNet(2012)의 구조와 논문 리뷰
오늘은 Deep한 CNN의 발전에 가장 큰 영향을 준 AlexNet(2012)에 대해 포스팅하고자 합니다. AlexNet은 2012년에 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 에서 우승을 차지한 아키텍처로, 이전
daeun-computer-uneasy.tistory.com
4. Overlapping Pooling

결론부터 먼저 말씀 드리자면, overlapping pooling 을 적용하여 overfitting 을 아주 약간 방지하였다고 합니다.
그렇다면 overfitting 이 무엇이며, 어떻게 overlapping pooling 이 overfitting 을 방지하였을까요 ?
overfitting :
[ 출처 : https://velog.io/@cnwns820/Overfitting ]
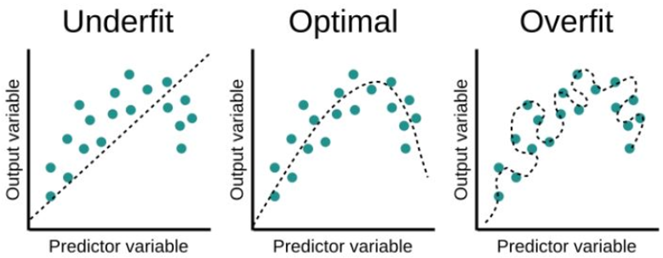
overfitting 의 개념은 위의 그림으로 설명이 가능합니다.
- Underfit, optimal, overfit 세 가지 경우에서 파란 점의 분포는 모두 동일합니다.
하지만 점들의 분포를 설명해주는 fitting curve 가 각각 다르다는 걸 볼 수 있죠.
- optimal 의 fitting curve 와 비교했을 때, overfit 의 fitting curve 는 존재하는 모든 점들을 이어주고 있습니다.
이는, 주어진 데이터 (=파란 점들)에 한해서는 완벽하게 설명(=점과 선이 연결)이 가능하다는 것을 의미합니다.
- 하지만 overfit 의 fiting curve에서 경향성이라는 것이 보이시나요?
주어진 데이터에 대해서는 너무나도 잘 맞아떨어지는 curve 이지만,
오히려 너무나도 잘 맞아떨어지기 때문에, (= 경향성을 무시하고, 점과 선이 연결되는 것에만 집중)
주어진 데이터가 아닌 새로운 데이터 (= 임의의 새로운 점 = testing 과정에서의 새로운 data ) 가 들어오게 되면
training 과정에서 미리 파악된 경향성이 없기 때문에, testing 성능 ( = 새로운 데이터에 대한 적용 능력)에 문제가 생기게 됩니다.
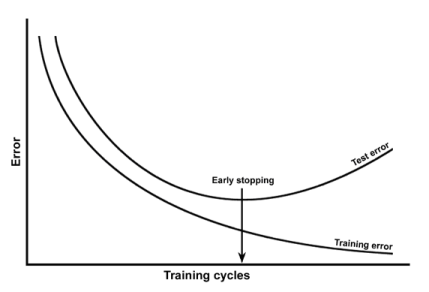
그래서 바로 위의 그림과 같이, training error 가 너무 낮으면, 오히려 test error 가 증가하게 되는 현상이 발생하는데
이를 overfitting (과적합) 이라고 합니다.
overlapping pooling :
그렇다면 어떻게 overlapping pooling 이 overfitting 을 방지하였는지,
우선 제가 이해한 대로 적어보겠습니다.
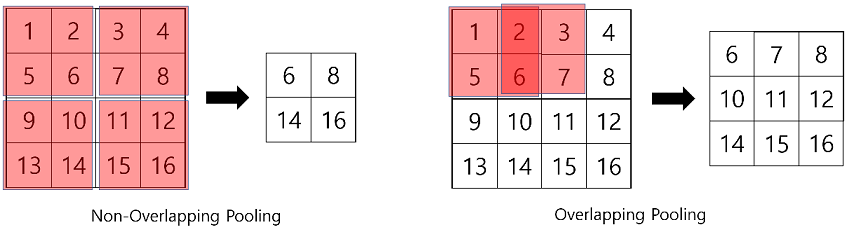
[ 출처 : https://bskyvision.com/421 ]
- 동일한 4x4 input 에 대해 max pooling 으로 계산된 두 결과( 2x2 , 3x3 )를 보시면,
먼저 4x4 input 에서 아래쪽의 값들이 훨씬 큰 값을 가지고 있습니다.
이러한 결과는 당연히 max pooling시 그대로 적용이 됩니다.
- 하지만 non-overlapping pooling 의 경우 6과 14 혹은 6과 16 사이에 매우 급격한(?) 변화가 존재하게 되는 반면
overlapping pooling 적용 시, 6과 14 사이에 (6 10 14 로 이어지는) 매끄러운 중간 과정이 포함이 되게 됩니다.
- 위에서 보여드린 fitting curve 에 이를 적용해서 생각해보자면,
fitting 의 목적은 data의 특정 분포를 설명할 수 있는 경향성을 얼마나 잘 파악할 수 있는지를 나타내기 위함입니다.
만약 6과 16 두 개의 데이터만 존재한다면, 그러한 경향성을 파악하는데 어려움이 있겠죠.
- 복잡하게 정리하였지만, 간단하게 말하자면 결국
overlapping pooling 을 통해 데이터 손실을 줄일 수 있기 때문이라 생각하면 편할 것 같습니다.
( 데이터 손실이 줄면, 그만큼 알고 있는 정보가 늘어나고, 그로 인해 갑작스럽게 튀는 값들에 대해서도 어느 정도 전후좌우의 맥락을 파악하기 수월하다... 라는 식으로 이해했습니다. )
overpooling 과 overfitting 에 관한 자세한 설명은 아래 링크를 참고하시면 좋을 것 같습니다.
Why does overlapped pooling help reduce overfitting in conv nets?
In the seminal paper on ImageNet classification with deep conv nets by Krizhevsky et al., 2012, the authors talk about overlapped pooling in convolutional neural networks, in Section 3.4. Pooling
stats.stackexchange.com
그 외 overfitting 을 해결하기 위한 다른 방법들도 사용하였습니다.
1.1. Reducing Overfitting - Data augmentation
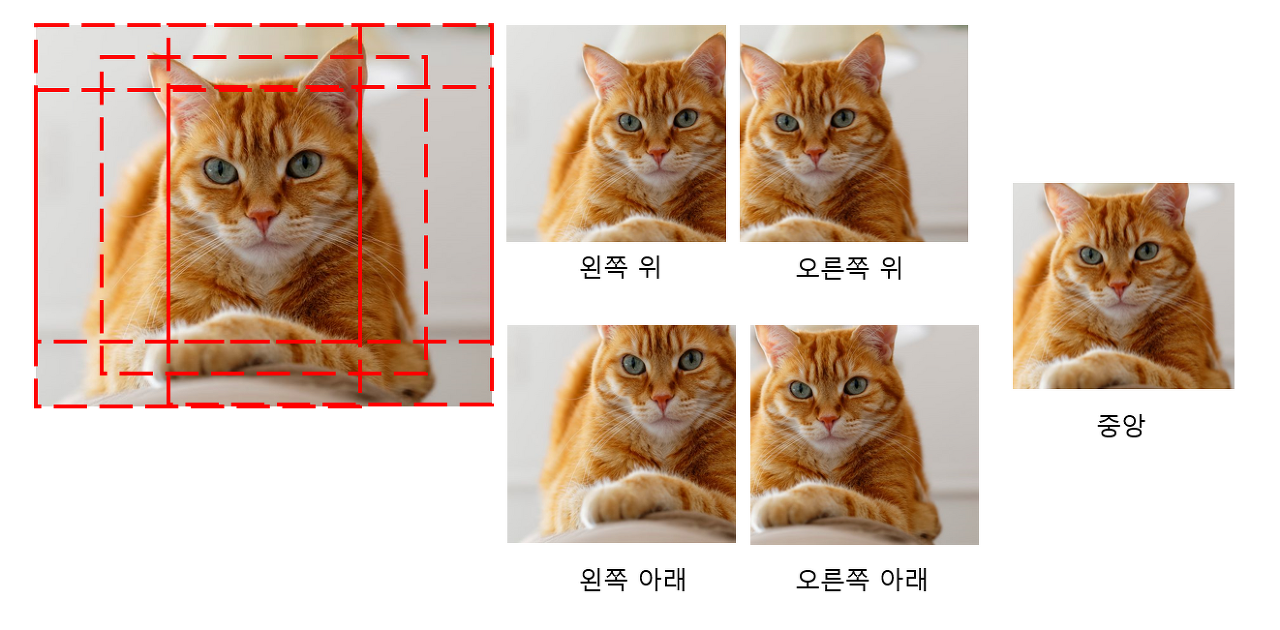
[ 출처 : https://velog.io/@hyesukim1/AlexNet-ImageNet-Classification-with-Deep-Convolutional-Neural-Networks]
- 말 그대로 data 의 수를 부풀려 주는 것을 data augmentation 이라고 합니다.
data augmentation 방법은 말 보다는 위의 그림을 통해 설명드리는 것이 가장 직관적이고 효과적일 것 같아 사진을 가져왔습니다.
- 첫 번째로는 '수평반전' 을 진행하여 동일한 이미지를 약간씩 다르게 복사하고,
두 번째로는 'PCA' 를 이용해 RGB 픽셀 값들에 약간씩 variation 을 주었습니다.
그리고 이러한 이미지들을 random한 크기로 잘라내어, 하나의 이미지에서 서로 조금씩 다른 여러 장의 이미지를 만들어냈습니다.


1.2. Reducing Overfitting - Dropout

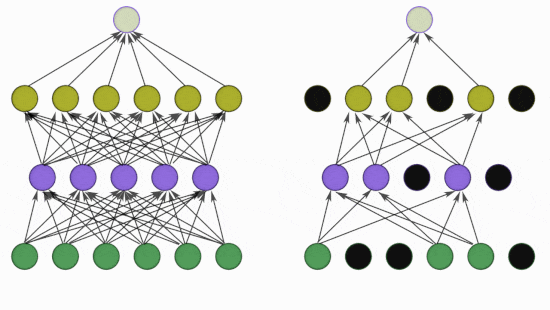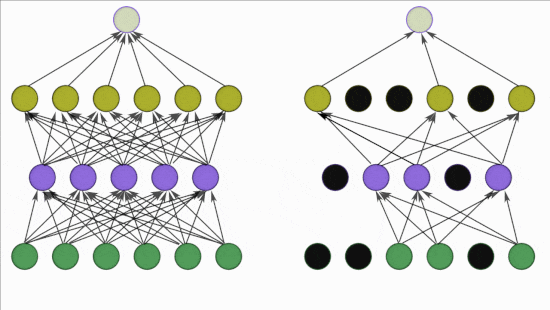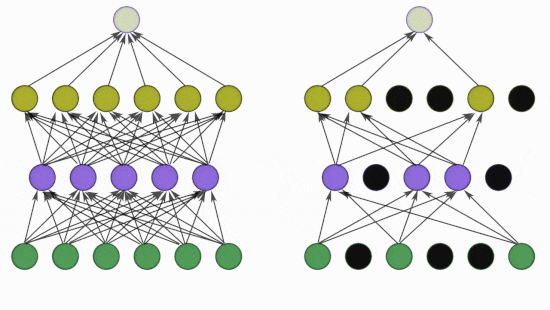
[ 출처 : https://medium.com/@adityaraj_64455/it-all-started-with-cnns-alexnet-3023b21bb891 ]
- Dropout 은 AlexNet 에서 처음 고안한 방법은 아니고, Hinton 교수가 2012년에 제안한,
그러니까 AlexNet 이 발표되었을 당시만 해도 overfitting 을 줄일 수 있는 획기적 방법이었습니다.
- Dropout 의 원리에 대해 있는 그대로 정리하자면, 신경망 내에 존재하는 일부 특정 input 혹은 일부 특정 node 에 대한 model 의 의존성 (= dependency) 을 없애 'co-adaptations of neurons'을 줄인다... 라고 되어 있습니다.
- 쉽게 이해하자면,
dropout 은 특정한 features 만 집중적으로 학습되는 것을 방지 !! 하는 것이며
이는 각각의 노트(node)들을 ramdom 하게 drop함으로써 가능하다 고 생각하시면 됩니다.
CNN은 물론이고 Python 도 처음 사용하는 입장에서 정리해 보았습니다.
찐뉴비 입장에서 하나씩 차근차근 배워 가보자! 라는 의미로 정리하는 내용인지라 설명에 많은 오류가 있을 수 있으니,
지적 및 도움 주시면 언제든지 감사하게 생각하겠습니다...
https://devlee247.com/papers/2022-06-13-alexnet/
[논문 리뷰 및 구현] AlexNet(2012) 리뷰 및 파이토치(PyTorch) 구현
AlexNet : ImageNet Classification with Deep Convolutional Neural Networks 파이토치(PyTorch) 구현한 피드입니다.
devlee247.com
아래의 code 는 제가 직접 작성한 것이 절대 아닌, 링크 되어있는 위 블로그에서 참고해 가져온 Code 입니다.
제가 직접 작성하여 공유하겠다는 목적이 절대 아니고,
다른 분들께서 구현해주신 code 를 보고 분석해보며 공부하는 입장에서 쓴 글이니 오해 없으시길 바라겠습니다 !
Google colab 에서 구현된 코드 입니다.
from google.colab import drive
drive.mount('alexnet')( LeNet-5 에서도 그대로 작성한 내용입니다. )
- PC 환경에서는 사용하고자 하는 Dataset을 적절한 경로에 위치시키면 사용할 수 있듯이,
Colab 은 Google drive 에 dataset을 따로 저장해두어야만 사용할 수 있습니다.
( torchvision.dataset 과 같이 제공되는 데이터셋 or url 링크를 이용하는 경우 ... 등등 제외 )
- 따라서 Colab 에서 나의 Google drive 에 접근할 수 있게끔 하는 코드 입니다.
그리고 이러한 과정을 어렵게 표현하면 'Colab 환경에서 마운트된 Google Drive 에 엑세스 하는 과정' .. 이라고 하네요.
import torch
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from torchsummary import summary- model 을 구현하고 학습시키는 데 필요한 다양한 라이브러리를 불러오기 위한 코드입니다.
def custom_imshow(img):
img = img.numpy()
plt.imshow(np.transpose(img, (1, 2, 0)))
plt.show()- 학습하는데 필수적인 코드는 아니지만, 작성해주신 분께서 편의를 위해 샘플 이미지를 시각적으로 보고자 정의한 부분입니다.
'def custom_imshow(img)' : 샘플 이미지를 시각화하기 위하여, 미리 img 를 입력로 받는 custom_imshow 함수를 정의합니다.
'np.transpose(img, (1,2,0))' : 만약 img 의 차원이 (batch_size, width, hegith) 이었다면, (각각 0, 1, 2 순서)
np.transpose(img, (1,2,0)) 를 사용하면 (width, height, batch_szie) 가 됩니다. (각각 1, 2, 0 순서)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize(227),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 4
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')'transform = transform.Compose( ~ ' :
- 다양한 변환 ( ToTensor + Resize + Normalize )을 각각 적용하기는 번거로우니,
'.Compose' 를 사용하여 transform 을 순차적 (+ 묶어서 한번에 )으로 적용할 수 있게 됩니다.
'trainset = torchvision.datasets.CIFAR10( ~ ' :
- 'torchvision.dataset' : CIFAR10 dataset 을 직접 다운로드하여 google drive 에 올려두지 않더라도,
torchvision.dataset 을 사용하여서 torch에서 제공하는 CIFAR10 dataset 을 학습에 사용할 수 있습니다.
- ' root = './data' ' : torchvision 에서 제공하는 CIFAR10 을 받아오게 될 경로를 설정해 줍니다.
- ' train = True ' = training 용 데이터셋 & ' train = False ' = testing 용 데이터셋 으로 나누어 저장합니다.
그리고 받아온 dataset 에 위에서 정의한 'transform' 을 적용합니다.
' train_loader = torch.utils.data.DataLoader( ~ ' :
- dataloader 는 받아온 dataset 을 한꺼번에 넘기는 것이 아니라, mini batch 단위로 쪼개어 나누어서 제공해주는 역할을 합니다.
따라서 위에서 'batch_size = 4' 라고 정의하였으니,
' batch_size = batch_size ' 를 사용하여 넘겨줄 배치의 크기를 정의해 줍니다.
이때 넘겨주는 dataset 은 당연히 앞에서 정의한 trainset 이 되겠습니다. ( ... Dataloader(trainset, batch_size .... )
- ' shuffle' = dataloader 에 의해 dataset 의 일부분을 를 넘겨줄 때 순서를 섞어서 넘겨줍니다.
- ' num_workers ' : 학습 도중 CPU 작업 시 사용할 코어의 개수를 정의해주는 파라미터 입니다.
- ' classes ' : MNIST 와 달리 CIFAR10 은 위에 적힌 (비행기, 차, 새, 고양이 ... ) 라벨 값을 갖는 dataset 입니다.
따라서 dataset 에 맞게 classes 를 지정해 줍니다.
sample_num = 694
custom_imshow(trainset[sample_num][0])
print(classes[trainset[sample_num][1]])- 위에서 샘플 이미지를 확인하기 위하여 'custom_imshow(img)' 를 정의했었습니다.
이제 torchvision.dataset 을 이용해 CIFAR10 dataset 을 trainset 에 받아왔으니,
받아온 dataset 의 샘플 이미지를 확인하고자 합니다.
- custom_imshow(img)에서, img 는 trainset에서 694번째 위치한 이미지 가 됩니다.
- [0]과 [1]의 의미는 다음과 같습니다.
torchvision.dataset 에 의해 제공되는 데이터셋은 1. 이미지 데이터 + 2. Label (class) 로 구성되어 있습니다.
따라서 custom_imshow( ~ [0]) 은 이미지 데이터를 출력하기 위함이고,
print( ~ [1]) 은 출력된 이미지의 Label (class)를 확인하기 위한 것 입니다.
참고로 출력 결과는 아래와 같은 비행기 사진이 나오네요.
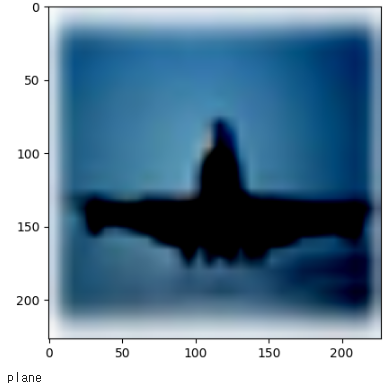
device = 'cuda' if torch.cuda.is_available() else 'cpu'' device = 'cuda' if torch.cuda.is_available() els 'cpu' :
- 'torch.cuda' 는 연산 과정에서 GPU 를 사용하기 위한 모듈입니다.
즉, ' if torch.cuda.is_available() ' : ' 말 그대로 GPU 사용이 가능하면 사용하고,
'else : 'cpu' : GPU 사용이 불가능하면 그냥 CPU 사용해라
라는 의미 입니다.
class Alexnet(torch.nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, 96, kernel_size=11, stride=4),
torch.nn.ReLU(inplace=True),
torch.nn.LocalResponseNorm(2),
torch.nn.MaxPool2d(kernel_size=3, stride=2)
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
torch.nn.ReLU(inplace=True),
torch.nn.LocalResponseNorm(2),
torch.nn.MaxPool2d(kernel_size=3, stride=2)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=True)
)
self.layer4 = torch.nn.Sequential(
torch.nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=True)
)
self.layer5 = torch.nn.Sequential(
torch.nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2)
)
self.avgpool = torch.nn.AdaptiveAvgPool2d((6,6))
self.classifier = torch.nn.Sequential(
torch.nn.Linear(6*6*256, 4096),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.5),
torch.nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return self.classifier(x)'class LeNet_5(nn.Module):
def __init__(self):
super(LeNet_5,self).__init__()' :
CNN 모델을 구현할 때면, 공식처럼 나오는 코드입니다.
있는 그대로 가져와서 써도 무방하지만
class 는 뭐고, 또 _init__, super 는 무엇인지.. 그 의미를 알고 싶어서 공부해보았습니다.
아래의 자료를 참고하시면 좋을 것 같습니다.
파이썬(Python): 클래스(class) 안 def __init__(self): 와 self 등을 제대로 이해하기
"def __init__(self):" 파이썬python을 약간이라도 다루기 시작한 사람이라면 이내 마주치는 구문이다. 개인적으로는 def __init__(self) 구문은 파이썬에서만 사용하는 함수로 안다. 다른 언어에서 본 적이
writingstudio.tistory.com
' self.layer1 = torch.nn.Sequential ···
····
def forward(self,x) : '
- AlexNet 의 구조를 있는 그대로 옮겨 적은 코드이므로, 분석할 내용이 딱히 없었습니다.
위에서 공부한 ReLU, LocalResponseNorm, MaxPool2d, Dropout 등의 개념이 그대로 들어가 있으며,
본문 가장 위에 있는 AlexNet architetuer 와 비교해서 보니 쉽게 이해가 되었습니다.
참고로 dropout(x) 는 x 의 확률로 dropout 시킨다는 의미입니다.
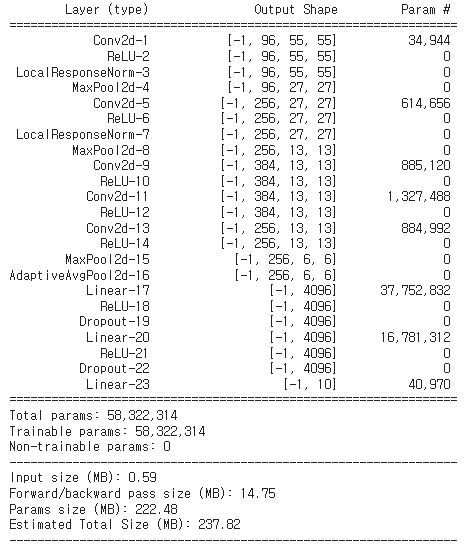
model = Alexnet(3, 10).to(device)
summary(model, input_size=(3, 227, 227), device='cuda')정의한 model = Alexnet 의 structure 를 요약해서 보여주기 위한 코드입니다.
'model = Alexnet(3,10).to(device)' :
- (3,10)에서 각각 3은 입력 채널의 수 (RGB), 10은 output class 의 수 (plane, dog, cat ···) 를 의미합니다.
왜냐하면 위에서
class Alexnet(torch.nn.Module):
def __init__(self, in_channels, num_classes):
라고 정의했기 때문입니다.
' summary(model, input_size=(3, 227, 227), device='cuda') ' :
input size 가 (3,227,227) 인 image 를 이용하면, 아래와 같이 model 의 구조 및 파라미터가 출력됩니다.
lr = 1e-4
epochs = 50
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)- learning rate 와 epoch, 그리고 loss function및 optimizer 를 정의해 줍니다.
for epoch in range(epochs):
print("\nEpoch ", epoch)
# train
print("\nTrain:")
model.train()
train_loss = 0
for i, (images, targets) in enumerate(train_loader):
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if ((i+1) % (len(train_loader) // 30) == 1) or i+1 == len(train_loader):
print('[%3d/%3d] | Loss: %.5f'%(i+1, len(train_loader), train_loss/(i+1)))
# val
print("\nValidation")
model.eval()
val_loss = 0
for i, (images, targets) in enumerate(test_loader):
images, targets = images.to(device), targets.to(device)
preds = model(images)
loss = criterion(preds, targets)
val_loss += loss.item()
if ((i+1) % (len(test_loader) // 3) == 1) or i+1 == len(test_loader):
print('[%3d/%3d] | Loss: %.5f'%(i+1, len(test_loader), val_loss/(i+1)))' for epoch in range(epochs) ' :
- 위에서 정의한 epochs 만큼 반복해서 학습시킵니다.
' model.train() ' , ' model.eval() ' :
- 모델을 학습 모드(train)와 평가 모드(evaluation) 로 설정합니다.
- ' train.loss = 0 ' : 초기값으로 loss 를 0으로 설정합니다.
' for i, (images, targets) in enumerate(train_loader):
images, targets = images.to(device), targets.to(device)
pred = model(images)
loss = F.cross_entropy(pred, targets)
train_loss += loss.item() ' :
- ' ~ enumerate(train_loader) ' : train_loader 에서 가져온 mini batch 단위로
trainset 에 있는 이미지와 라벨(target)를 분리(unpacking)합니다.
- 그 후, 분리된 images 를 model 에 넣은 것을 pred 로 정의하고
model에서 출력된 값 (= pred)과 target 을 비교하여 loss 를 정의합니다.
- train_loss 는 이전의 loss 값에 점진적으로 더해가며 계산합니다.
' optimizer.zero_grad()
loss.backward()
optimizer.step() ' :
- 이 부분은 Pytorch 를 사용한 다른 model 에서도 똑같이 쓰입니다.
왜냐하면 gradient descent 를 이용해서 parameters 를 업데이트한다는 개념은 동일하니까 !
- 'opt.zero_grad()' 는 optimizer 의 gradient 를 초기화 하는 역할을 한다.
매번 새로운 batch 가 진행될 때 마다 새로운 gradient 를 계산해야 하니까!
- 'loss.backward' : backpropagation 을 사용해 grdient 를 계산합니다.
- 'opt.step()' : 앞에서 계산한 grdient 들을 사용하여서 optimizer 가 갖는 parameters 를 전부 업데이트 합니다.
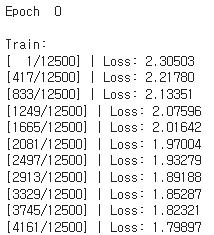
if ((i+1) % (len(train_loader) // 30) == 1) or i+1 == len(train_loader):
print('[%3d/%3d] | Loss: %.5f'%(i+1, len(train_loader), train_loss/(i+1))) :
아래와 같이 Train 진행 상황과 Loss 값을 출력하기 위한 코드입니다.
'Vision > Machine Learning' 카테고리의 다른 글
| [ML] 초간단 ML History 1 (0) | 2023.06.23 |
|---|---|
| GAN (Generative Adversarial Networks ) (0) | 2023.06.20 |
| Context Encoder (0) | 2023.06.17 |
| SRCNN ( Super-Resolution CNN ) (0) | 2023.06.16 |
| LeNet-5 (0) | 2023.06.15 |


