( 참고! 최초의 GAN이 발표된 이후, GAN 의 개념을 이용한 다양한 모델들이 나왔는데,
VanillaGAN 은 최초의 GAN model입니다.
본 포스팅에서는 편의상 GAN 이라고 하겠습니다. )
( GAN paper ↓↓ )
https://arxiv.org/abs/1406.2661
Generative Adversarial Networks
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that
arxiv.org
CV 분야를 공부하다 보니, '생성모델' 이라는 개념이 굉장히 자주 등장하더라고요.
사실 처음에는, 무언가를 생성한다 라고 해봤자 어차피 가짜 아니야? 라는 생각에 아무 의미없는 것 처럼 보였는데
최근 제가 구현하고 싶어하는 Image Inpainting, Depth Estimation, Denoising 등등 너무나도 많은 분야에서
'생성모델' 을 응용해서 적용시키고 있더라고요.
그만큼 생성모델 관련 기술이 어마어마하게 발전했다는 거겠죠?
아무튼 이러한 이유로 생성모델 에 관해서 공부해보고자 했습니다.
AE, GAN, Diffusion model 그리고 Transformer 기반의 다양한 생성 모델도 있다고 하는데..
우선 차근차근 공부하는 입장에서, 먼저 대표적인 생성모델인 GAN 에 대해서 공부해보고자 했습니다.
본 포스팅에서는 논문에서 설명하는 모델의 특징 및 구조 등을 간단하게 파악해보고,
구현된 코드를 분석해보고자 합니다.
GAN 및 코드를 공부하고 글을 작성하는데 있어, 아래의 사이트에서 많은 도움을 받았습니다.
아래는 포스팅 작성에 참고하여 많은 도움을 받은 사이트들의 링크 입니다 !
https://bestkcs1234.tistory.com/53
GAN (Generative Adversarial Nets) 생성적 적대 신경망 논문 리뷰/번역 - 2014
Goodfellow, Ian, et al. "Generative adversarial networks." Communications of the ACM 63.11 (2020): 139-144. 논문 원문 : https://arxiv.org/abs/1406.2661v1 GAN 은 데이터를 생성해내는 모델과, 생성된 모델 vs 원본을 구별해내는 모
bestkcs1234.tistory.com
https://tobigs.gitbook.io/tobigs/deep-learning/computer-vision/gan-generative-adversarial-network
(GAN)Generative Adversarial Nets 논문 리뷰 - Tobigs
이 방정식을 D의 입장, G의 입장에서 각각 이해해보면, -먼저 D의 입장에서 이 value function V(D,G)의 이상적인 결과를 생각해보면, D가 매우 뛰어난 성능으로 판별을 잘 해낸다고 했을 때, D가 판별하
tobigs.gitbook.io
https://www.youtube.com/watch?v=AVvlDmhHgC4
( 실제 GAN 논문에서는 모델을 설명하기 위해서, 통계학적 지식을 비롯한 많은 수학적 과정이 나옵니다.
제가 작성하는 Deeplearning model 관련 포스팅 목적은
나중에 제가 수행하고자 하는 task 에 활용될 수 있을만한 모델들을 찾아보기 위해
다양한 모델을 살펴보고, 사용된 개념 + 구현된 코드 를 대략적으로 파악하는 위함입니다.
따라서 전체적인 흐름이나 코드를 간략하게 이해하는데 있어 반드시 필요하지는 않다고 판단되는 수학적 과정들은
과감하게 건너뛰고 공부하였습니다.
다만 그런 부족한 부분들을 공부하는데 도움이 되는 사이트들은 링크로 남겨두도록 하겠습니다 ! )
GAN ( Generative Adversarial Networks, 적대적 생성 네트워크 ) 은 이름 그대로
'적대적' 인 방법으로 무언가를 '생성'해 내는 머신러닝 프레임워크 입니다.
아래의 그림과 같이 model 이 학습될 수록 점점 더 선명한 (= 즉 진짜같은) 가짜 이미지들이 생성이 됩니다.

[ 출처 : https://debuggercafe.com/vanilla-gan-pytorch/ ]
Generative ( 생성 )
위에서 잠깐 언급하였지만, GAN 이 '생성'하는 것은 바로 가짜 이미지(fake image) 입니다.
GAN은 이미 학습된 이미지의 분포와 유사한 분포를 갖는 새로운 이미지, 즉 가짜 얼굴, 가짜 손글씨 사진 등등···
과 같은 가짜 이미지(fake image)를 생성해냅니다.
여기서 유사한 '분포'라 함은 다음과 같습니다.
예를 들어 MNIST 이미지의 숫자 '1' 을 생각해봅시다.
각기 다른 pixel 값을 갖는 '1 images' 들은 서로 전부 다 조금씩 다르지만,
' 1 images '들은 공통적으로 흰 줄( White pixel value = 255) 이 세로 방향으로 길게 그어져있고, 가로 방향으로는 긴 흰색 줄이 거의 존재하지 않는다... 라는 경향성을 파악할 수 있습니다.
그래서 ' 1 images ' 들에서 상대적으로 값이 큰 pixel 들( = 흰색과 가까운 pixel들)은 주로 '가운데 세로줄' 방향으로 분포해있을 것이고,
생성된 가짜 '1 image' 는 이러한 분포를 기반으로 '가운데 세로줄' 을 갖는 가짜 image 를 새롭게 생성해낼 것 입니다.
Adversarial ( 적대적 )
GAN 이 가짜 이미지를 생성한다는 것은 알겠는데, 그렇다면 '적대적' 이라는 말이 무슨 의미일까?
이를 알기 위해서는 Generator(G) 와 Discriminator(D)의 개념을 알아야 합니다.
Generator 와 Discriminator의 개념은 아래에서 조금 더 자세하게 설명드리겠지만, 간단하게 설명드리면 다음과 같습니다.
Generator 는 말 그대로 '가짜 이미지'를 생성하는 녀석이라는 것을 직관적으로 이해하실 수 있을 겁니다.
일단 생성된 '가짜 이미지'는 당연히 '진짜 이미지'와 일단 비슷하게 생성이 될텐데,
" 그렇다면 '가짜 이미지'가 얼마나 '진짜 이미지'처럼 보이는지,
또 얼마나 구별하기 힘들 정도로 비슷한지를 누가 어떻게 판단하지 ? "
라는 질문을 할 수 있습니다.
이러한 과정 ( 진짜 이미지와 가짜 이미지를 구별하는 작업 )을 하는 녀석을 Discriminator 라고 합니다.
Discriminator 는 '가짜 이미지'는 가짜 이며 '진짜 이미지'는 진짜 라고 판별하고자 하겠지만, Generator(G) 는 이러한 Discriminator(D) 를 속이고 싶어 합니다.
즉 자신(G)이 만든 '가짜 이미지'를 D에게 보여주었더니, D가 "이거는 진짜 이미지야" 라고 말하며 속아주길 원합니다.
물론 처음부터 G 가 D 를 속이기는 쉽지 않겠죠.
그러므로 수많은 반복 과정 속에서 G는 D를 속이고, D는 G에게 속지 않게끔,
( = 즉 G는 D가 속을 만큼 진짜같은 '가짜 이미지'를 만들고,
D 는 G에게 속지 않도록 진짜는 진짜이고, 가짜는 가짜라고 정확하게 구별할 수 있게끔 )
즉 G와 D 서로 '적대적'으로 학습이 되기 때문에 Adversarial 이라는 이름이 붙게 되었습니다.
이러한 G와 D 의 관계를 잘 표현해주는 유명한 그림이 있습니다.
본 논문의 저자가 아래와 같은 방식으로 GAN 의 원리를 설명했다고 하네요.
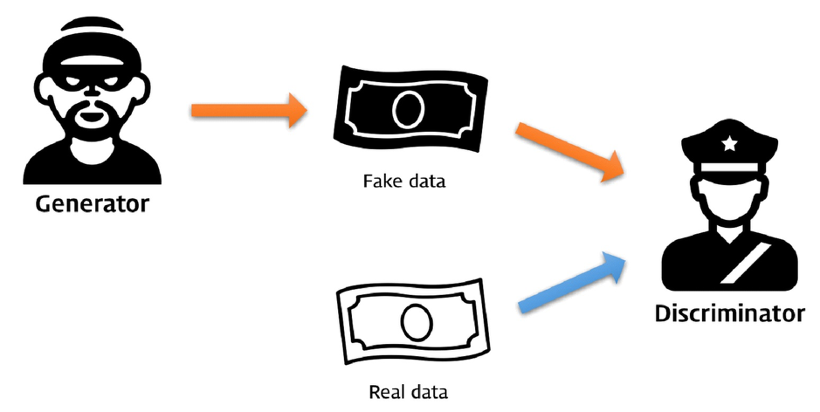
[ 출처 : https://files.slack.com/files-pri/T25783BPY-F9SHTP6F9/picture2.png?pub_secret=6821873e68 ]
Generator (도둑) 가 Real data (진짜 지폐) 를 보고 참고하여 Fake data (위조 지폐) 를 만듭니다.
만들어진 Fake data (위조지폐) 를 Discriminator ( 경찰 ) 이 진짜 지폐인지, 위조 지폐인지 판별합니다.
Generator (도둑)은 Discriminator (경찰)을 속이기 위해 Real data(진짜 지폐) 같은 Fake data(위조 지폐) 를 만들고,
Discriminator (경찰)은 최대한 정확하게 Fake data (위조 지폐)를 판별해내려 합니다.
( 참고! )
이상적으로 잘 학습된 GAN 이 다양한 fake image 를 생성해줬으면 싶지만,
실제로는 GAN은 Mode Collapse 라는 문제를 종종 겪게 됩니다.
Mode Collapase 는 G 가 다양한 이미지가 아닌 한 쪽으로 편향된 ( = 계속해서 거의 동일한 이미지만 출력 )
이미지만을 생성해내는 현상을 의미합니다.
이러한 Mode Collapse 는 Vanilla GAN 이후 다양한 GAN model 들이 만들어지면서 어느 정도 개선되었습니다.
Mode Collapse 에 관한 내용은 차후에 작성할 GAN model 글에서 정리할 예정입니다.
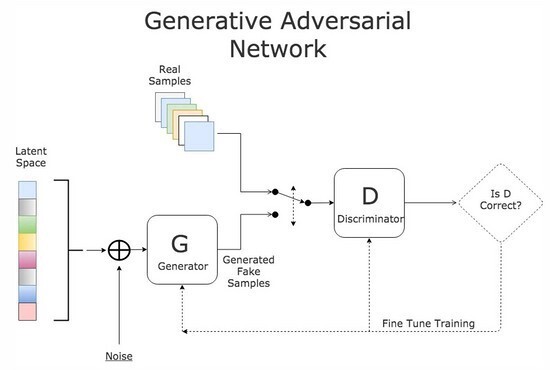
[ 출처 : https://lv99.tistory.com/57 ]
위의 그림은 GAN network 를 도식적으로 잘 표현한 그림입니다.
앞에서 설명드린 내용과 비교해 보시면, 각각의 부분들이 무엇을 의미하는 지 대충 감이 오실거라 생각합니다.
다만, Generator (G) 좌측에 Noise 라고 표시된 부분이 어떤 것인지 잘 이해가 되지 않을 수 있습니다.
그냥 쉽게 이해하기 위해 단순하게 생각해 보자면, 어떠한 랜덤한 분포가 들어오더라도 학습된 모델을 통과하게 되면
무의미한 데이터(random value)에서 유의미한 데이터(Fake Image)를 출력하도록 학습시킨다!
라고 받아들이면 될 것 같습니다.
저도 완벽하게 이해가 되지는 않았지만, 이 'Noise'가 어떤 의미인지 아래의 블로그에서 자세히 설명되어 있으니 참고하시면 좋을 것 같습니다.
https://data-newbie.tistory.com/424
Why Do GANs Need So Much Noise? - 리뷰
GAN에 왜 그렇게 많은 노이즈가 필요한가?라는 주제로 미디엄 글이 있어서, GAN 쪽에서 이런 원론적인 것에 대해 관심이 많기 때문에 읽어보려고 한다. GAN (Generative Adversarial Networks)은 오래된 "실제
data-newbie.tistory.com
Adversarial nets
그렇다면 위 내용 (G는 D를 속이고, D는 G에게 속지 않는 과정) 을 수식으로 표현하면 어떻게 될까요?
수식을 보기 전 먼저 다시 한 번 간단하게 말로 정리해 보겠습니다.
Discriminator (D) 가 진짜인지 가짜인지 모르는 임의의 이미지를 보고 내릴 수 있는 결과는 크게 나누면 2가지 경우일 것 입니다.
" 이 이미지는 진짜다. " or " 이 이미지는 가짜다. "
전자의 경우, 즉 이미지의 진위여부에 관계없이, D가 판단하기에 이미지가 진짜라면 1이 출력이 되고
후자의 경우, 즉 이미지의 진위여부에 관계없이, D가 판단하기에 이미지가 가짜라면 0이 출력이 된다고 가정해보죠.
그렇다면 이제 아래의 과정을 이해할 수 있습니다 !
1. Real image 를 D에게 보여주었을 때, 이 이미지는 진짜 이미지 이므로
우리는 D가 1 (진짜)이라고 대답해주길 원합니다.
2. 또한 G가 만든 이미지를 D에게 보여주었을 때,
G 가 만든 이미지는 아무리 비슷해 보이더라도 결국은 만들어진 Fake image 이기 때문에,
우리는 D 가 0 (가짜)이라고 대답해주길 원합니다.
위 내용이 이해가 되셨다면, 본격적으로 1번과 2번 과정을 수학적으로 표현해 보겠습니다.
↓↓↓↓↓↓↓↓
먼저 변수를 설정해야 겠죠.
Real data 를 x 라고 하고, Fake data 를 z 라고 합시다. 그리고 G는 이 Fake data (z) 로 부터 Fake image 를 생성합니다.
( Fake data z 란 fake image 자체가 아니며, 위에서 말씀드린 Noise 를 의미합니다 !! )
결국 G에 Fake data 를 대입함으로써 Fake image 가 출력이 되므로,
Fake image = G(Fake data) = G(z) 로 표현이 됩니다.
1번 에서 Real image ( = x ) 를 D 에게 보여주면 1 이라고 대답해주길 원한다고 했죠?
즉, D(x) = 1 이 출력되기를 원한다고 해석할 수 있습니다.
2번 에서 Fake image ( = G(z) ) 를 D에게 보여주면 0 이라고 대답해주길 원한다고 했죠?
즉, D( G(z) ) = 0 이 출력되기를 원한다고 해석할 수 있습니다.
위 내용만 이해되셨으면,
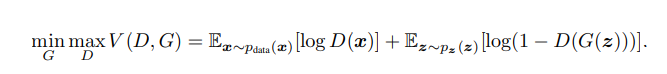
논문에서 설명하는 위 수식을 쉽게 이해할 수 있습니다.
log 는 단순히 각 항의 범위를 변형시키기 위해 추가된 것이며, E는 기댓값(expectation) 을 의미합니다.
pdata(x)는 real data 생성분포를 , pz(z) 는 noise variable 를 의미 합니다.
쉽게 말하면, x~pdata 는 x 가 real data 내에 속하며, z~pz(z) 는 z 가 fake data 에 속함을 의미합니다.
D와 (1-D) 가 [0,1] 의 범위를 갖고 있기 때문에 log(D)와 log(1-D) 의 범위는 [-∞,0] 를 갖게 됩니다.
일반적으로 Loss function 은 0에 수렴하는 값을 갖고 싶어하죠?
그렇다면, 첫 번째 항 logD(x) 이 '0'이 되기 위해서는, D(x) = 1이 되어야 합니다.
또한, 두 번째 항 log(1-D(G(z)))가 '0'이 되기 위해서는, D(G(z)) = 0 가 되어야 합니다.
이는 위에서 먼저 정리했던 1번과 2번의 결과와 완벽하게 일치합니다.
여기서 추가적으로, min max V(D,G) 는 무엇일까요?
말로 간단하게 설명드리자면,
1) min_G : G 가 포함되어 있는 부분 ( log(1-D(G(z))) )은 최소가 되게 해줘.
왜냐하면, log(1-D(G(z))가 최소가 되려면, D(G(z)) = 1, 즉 G가 만든 이미지를 보고 D가 속기를 원하기 때문.
2) max_D : D 가 포함되어 있는 부분( logD(x) & log(1-D(G(z))) )은 최대가 되게 해줘.
왜냐하면, 진짜 이미지 D(x) = 1(진짜)라고 판단해서 logD(x) 가 0이 되기를 원하고
가짜 이미지는 G(D(z)) =0(가짜)라고 판단해서 log(1-D)가 0가 되기를 원하기 때문. ( [-∞,0] 에서 최대 )
논문에서는 아래와 같이 표현했네요.


그렇다면 G 와 D는 어떻게 업데이트 될까?
라는 질문을 하실 수 있습니다.
위 질문에 대한 답은 아래의 구현된 코드를 분석해보면서 동시에 정리해 보도록 하겠습니다.
사실 저는 단순히 코드 구현을 위해 논문의 아이디어를 파악하는 것이 주목적이었고,
위 내용까지만 이해하고 보니 아래의 코드를 구현하는데 큰 어려움이 없었습니다.
코드 구현 자체에는 아이디어 및 모델 구조, 손실 함수, 데이터 전처리 과정 등만 익히면 어느 정도 이해가 되더라고요 ...
그래서 이론과 관련된 포스팅은 여기서 마치기로 하였습니다.
다만, 더 자세한 논문 내용이나 수학적 이론에 대해 공부해보고 싶으신 분들은 아래의 링크 + 포스팅 가장 맨 위의 링크를 참고하신다면 많은 도움이 될 것이라 생각합니다 !
https://deepapple.tistory.com/1
Generative Adversarial Nets
본 글은 Ian J.Goodfellow의 Deep Learning책과 14년도에 발표된 Generative Adversarial Nets의 내용을 기반으로 작성되었으며 제 주관적인 의견이 반영되어있습니다. 현재 시점에서, 약 2512건의 논문에 reference
deepapple.tistory.com
https://hyeongminlee.github.io/post/gan002_gan_math/
[GAN]GAN with Mathematics | Hyeongmin Lee's Website
이번 포스트에서는 앞에서 배운 KLD와 JSD를 이용하여 GAN에 대해 조금 더 수학적으로 파고 들어 보겠습니다. GAN은 단순히 이미지를 생성하는 알고리즘이 아닙니다. 주어진 데이터의 분포를 파악
hyeongminlee.github.io
CNN은 물론이고 Python 도 처음 사용하는 입장에서 정리해 보았습니다.
찐뉴비 입장에서 하나씩 차근차근 배워 가보자! 라는 의미로 정리하는 내용인지라 설명에 많은 오류가 있을 수 있으니,
지적 및 도움 주시면 언제든지 감사하게 생각하겠습니다...
https://github.com/Yangyangii/GAN-Tutorial/blob/master/MNIST/VanillaGAN.ipynb
GitHub - Yangyangii/GAN-Tutorial: Simple Implementation of many GAN models with PyTorch.
Simple Implementation of many GAN models with PyTorch. - GitHub - Yangyangii/GAN-Tutorial: Simple Implementation of many GAN models with PyTorch.
github.com
아래의 code 는 제가 직접 작성한 것이 절대 아닌, 링크 되어있는 위 Github 에서 참고해 가져온 Code 입니다.
제가 직접 작성하여 공유하겠다는 목적이 절대 아니고,
다른 분들께서 구현해주신 code 를 보고 분석해보며 공부하는 입장에서 쓴 글이니 오해 없으시길 바라겠습니다 !
Google colab 에서 구현된 코드 입니다.
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
import numpy as np
import datetime
import os, sys
from matplotlib.pyplot import imshow, imsave- model 을 구현하고 학습시키는 데 필요한 다양한 라이브러리를 불러오기 위한 코드입니다.
MODEL_NAME = 'VanillaGAN'
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")- MODEL_NAME 을 정의하고, 또 cuda 를 사용하네요.
' device = torch.device( 'cuda' if torch.cuda.is_available() els 'cpu' ):
- 'torch.device( 'cuda' ~ 는 연산 과정에서 GPU 를 사용하기 위한 모듈입니다.
즉, ' if torch.cuda.is_available() ' : ' 말 그대로 GPU 사용이 가능하면 사용하고,
'else : 'cpu' : GPU 사용이 불가능하면 그냥 CPU 사용해라
라는 의미 입니다.
def get_sample_image(G, n_noise):
z = torch.randn(100, n_noise).to(DEVICE)
y_hat = G(z).view(100, 28, 28)
result = y_hat.cpu().data.numpy()
img = np.zeros([280, 280])
for j in range(10):
img[(j-1)*28:(j)*28] = np.concatenate([x for x in result[(j-1)*10:(j)*10]], axis=-1)
return img학습에 필수적으로 요구되는 코드는 아닙니다.
하지만 학습 결과를 이미지 상으로 출력하기 위해 'get_samle_image' 를 정의합니다.
def get_sample_image(G, n_noise) :
- G (Generator) 와 n_noise 를 입력 변수로 받는 'get_sample_image' 라는 함수를 설정해주네요.
z = torch.randn(100, n_noise).to(DEVICE) :
- 위에서 Generator 는 random noise 를 입력으로 받아, 이로 부터 fake image 를 생성한다고 말씀드렸죠?
이 때, torch.randn(100, n_noise) 은 100 x n_noise 의 크기로 random noise 를 생성해달라는 의미입니다.
따라서 z 는 torch.randn() 를 사용하여, 평균이 1이고 표준편차가 1인 임의의 100x(n_noise) size의 random noise 를 생성해 줍니다.
- 그리고 계산된 결과를 GPU (DEVICE) 로 보내라고 하네요.
y_hat = G(z).view(100, 28, 28) :
- A.view(100,28,28)은 A 를 (100,28,28) 형태로 변형하라는 뜻입니다.
(100,28,28)은 배치 형태가 100개의 샘플을 가지며, 각각의 샘플은 28x28 size의 이미지를 갖게 됩니다.
- 따라서 위에서 생성된 random noise z 를 G에 넣어 생성된 가짜 이미지 G(z)를, (100,28,28) 형태로 변형시킨 것이 y_hat 이 됩니다.
result = y_hat.cpu().data.numpy() :
- 계산된 y_hat 을 CPU로 넘긴 다음에 numpy 형태로 변형하라네요.
아마 result 이다 보니, 결과를 최종적으로 확인하기 위해 GPU 에서 연산된 결과를 CPU로 불러오는 것 같습니다.
- 단순히 GPU에서 CPU로 넘긴것이기 때문에, 형태는 그대로 (100,28,28)일까요?
img = np.zeros([280, 280]) :
- 작성된 코드의 가장 아 부분래 결과를 먼저 보시면, 10x10 size 의 fake MNIST images 들이 있습니다.
따라서 (28x10)x(28x10) 에 맞추어서 생성된 총 100개의 fake images 의 결과를 보기 위해,
빈 도화지를 미리 준비해둔 것이라 생각하시면 됩니다.
for j in range(10):
img[(j-1)*28:(j)*28] = np.concatenate([x for x in result[ (j-1)*10 : (j)*10]], axis=-1)
return img
- result 에서 계산된 결과의 형태는 (100,28,28)일 것 입니다.
따라서 j의 범위가 1 부터 10까지 일 때, result[ (j-10)*10 : (j)*10, axis = -1 ]은 (axis = -1 : 첫 번째 차원 )
각각 반복 회수 당 10개의 샘플 이미지를 (280x280) size 의 비어 있는 영행렬에 할당 (concatenate) 시킵니다.
빈 도화지(img)에 만들어 진 fake image 결과(result)를 덮어씌운다고 생각하시면 됩니다.
class Discriminator(nn.Module):
def __init__(self, input_size=784, num_classes=1):
super(Discriminator, self).__init__()
self.layer = nn.Sequential(
nn.Linear(input_size, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, num_classes),
nn.Sigmoid(),
)
def forward(self, x):
y_ = x.view(x.size(0), -1)
y_ = self.layer(y_)
return y_첫 줄에서 바로 알 수 있다시피 Discriminator 를 정의하는 코드이네요.
'class Discriminator(nn.Module) ~ ' :
- Architecture 를 짜는 과정이다 보니 nn.Module 을 상속받아서 구현하는 건 다른 모델에서와 동일하고
LeakyReLU 를 사용했다는 것이 이 전에 리뷰한 논문들과는 조금 다르네요.
'y_ = x.view(x.size(0), -1)' ~ :
- x.view() 는 x 의 크기를 () 안의 값에 맞게 변형시키라는 뜻 입니다.
- ()안에 x.size(0)과 -1 이 들어가 있네요.
(x.size(0),-1)은 곧 첫 번째 차원인 x.size(0)만 지정해둔 것입니다.
즉 x.size(0) = '첫 번째 차원' 만 그대로 유지하고, 나머지 (-1) 은 알아서 자동으로 계산해
라는 뜻 입니다.
- 그리고 그렇게 형태가 변형된 x 값을 위에서 정의한 layer에 입력시키 라네요. ( = 'self.layer(y_)' )
class Generator(nn.Module):
def __init__(self, input_size=100, num_classes=784):
super(Generator, self).__init__()
self.layer = nn.Sequential(
nn.Linear(input_size, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, num_classes),
nn.Tanh()
)
def forward(self, x):
y_ = self.layer(x)
y_ = y_.view(x.size(0), 1, 28, 28)
return y_마찬가지로 첫 줄에서 바로 알 수 있다시피 Generator 를 정의하는 코드이네요.
전체적인 형태가 Discriminaor 와 동일하므로 넘어가도록 하겠습니다.
batch_size = 64
n_noise = 100
max_epoch = 50
step = 0
n_critic = 1
D = Discriminator().to(DEVICE)
G = Generator(n_noise).to(DEVICE)학습에 필요한 parameters 를 정의합니다.
- n_noise 는 Generator 의 입력으로 들어가게 될 random noise 의 크기가 됩니다
'n_critic = 1' :
사실 이 부분을 위 글에서 설명하지 않았습니다.
결론부터 말하자면, G와 D 는 번갈아가면서 업데이트 되게 되는데, [ D 를 k 번 업데이트 후 → G 를 1번 업데이트... ]
과 같은 cycle 을 사용자가 설정할 수 있습니다.
이 때 'n_critic' 은 k 를 의미하며, 만약 n_critic = 2 라면 결국 [ D → D → G ] 순서로 업데이트 시키는 것 입니다.
이런 식으로 학습을 시키는 이유는 아래의 링크에 자세히 설명이 되어 있습니다.
https://tobigs.gitbook.io/tobigs/deep-learning/computer-vision/gan-generative-adversarial-network
(GAN)Generative Adversarial Nets 논문 리뷰 - Tobigs
이 방정식을 D의 입장, G의 입장에서 각각 이해해보면, -먼저 D의 입장에서 이 value function V(D,G)의 이상적인 결과를 생각해보면, D가 매우 뛰어난 성능으로 판별을 잘 해낸다고 했을 때, D가 판별하
tobigs.gitbook.io
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],
std=[0.5])]
)- Dataset 을 있는 그대로 입력하는 것이 아니라 정규화 (평균 = 0.5, 표준편차 = 0.5) 시킨 후 입력합니다.
이는 model 의 입장에서 볼 때, 데이터의 분포를 일정하게 조정할 경우 dataset을 일반화시키기 편리해 진다고 하며
결국 model이 더 잘 수렴하게 되어 빠르고 정확하게 학습될 수 있게 됩니다.
mnist = datasets.MNIST(root='../data/', train=True, transform=transform, download=True)
data_loader = DataLoader(dataset=mnist, batch_size=batch_size, shuffle=True, drop_last=True)'mnist = datasets.MNIST(~ ' :
- 위에서 'from torchvision import datasets' 을 써줬으므로, 바로 'datasets.MNIST' 를 사용합니다.
- 'torchvision.dataset' 을 사용함으로써, 굳이 MNIST dataset 을 직접 다운로드해서 google drive 에 올려두지 않더라도
torch에서 제공하는 CIFAR10 dataset 을 학습에 사용할 수 있습니다.
- ' root = './data' ' : torchvision 에서 제공하는 MNIST 을 받아오게 될 경로를 설정해 줍니다.
- ' train = True ' = training 용 데이터셋 & 만약 ' train = False ' 일 경우 testing 용 데이터셋 으로 나누어 저장합니다.
그리고 받아온 dataset 에 위에서 정의한 ' transform = transform' 을 적용합니다.
' data_loader = torch.utils.data.DataLoader( ~ ' :
- 위에서 'from torch.utils.data import DataLoader' 를 써줬으므로, 바로 ' ~ = DataLoaderd( ~ ' 를 사용합니다.
- Dataloader 는 받아온 dataset 을 한꺼번에 넘기는 것이 아니라, mini batch 단위로 쪼개어 나누어서 제공해주는 역할을 합니다.
따라서 위에서 'batch_size = 4' 라고 정의하였으니,
' batch_size = batch_size ' 를 사용하여 넘겨줄 배치의 크기를 정의해 줍니다.
이때 넘겨주는 dataset 은 당연히 앞에서 정의한 mnist 가 되겠습니다. ( ... Dataloader(mnist, batch_size .... )
- ' shuffle' : dataloader 에 의해 dataset 의 일부분을 를 넘겨줄 때 순서를 섞어서 넘겨줍니다.
- ' drop_last = True ' :
만약 총 데이터 개수가 100개 이고, batch size 가 30 이라고 가정해 봅시다.
그렇다면 30 30 30 씩 총 3개의 batch 가 만들어질 텐데, 나머지 10개의 데이터는 batch size 를 만족하지 못하여서 남게 됩니다. 이 때 이 남아있는 10개의 데이터를 버리느냐, 아니면 유지하느냐를 결정하는 것이 drop_last 입니다.
drop_last = True 로 설정하면 10개의 데이터를 버리고, False 인 경우 유지합니다.
criterion = nn.BCELoss()
D_opt = torch.optim.Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
G_opt = torch.optim.Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))D 와 G 각각의 optimizer 를 설정해 줍니다.
D_labels = torch.ones(batch_size, 1).to(DEVICE) # Discriminator Label to real
D_fakes = torch.zeros(batch_size, 1).to(DEVICE) # Discriminator Label to fake개인적으로는 D_labels 과 D_fakes 를 설정하여서,
뒤에 나올 loss function 에 적용하는 것이 아마 이 코드에서 가장 핵심적인 아이디어이지 않을까 싶습니다.
torch.ones 은 모든 요소가 1인 행렬을 의미하고 ( 따라서 D_labels 은 크기가 (batch_size)x1 이며 모두 1로 이루어짐 )
torch.zeros 는 모든 요소가 0인 행렬을 의미합니다. ( 따라서 D_fakes 는 크기가 (batch_size)x1 이며 모두 0로 이루어짐)
if not os.path.exists('samples'):
os.makedirs('samples'학습에 필수적으로 요구되는 코드는 아닙니다.
하지만 학습 결과를 저장하는 경로를 설정해주는 코드입니다.
'if not os.path.exists(~ ' : 만약 'samples' 라는 경로가 존재하지 않는다면
'os.makedirs(~' : 'samples' 라는 directory 를 만들어.
라는 뜻입니다.
for epoch in range(max_epoch):
for idx, (images, _) in enumerate(data_loader):
x = images.to(DEVICE)
x_outputs = D(x)
D_x_loss = criterion(x_outputs, D_labels)
z = torch.randn(batch_size, n_noise).to(DEVICE)
z_outputs = D(G(z))
D_z_loss = criterion(z_outputs, D_fakes)
D_loss = D_x_loss + D_z_loss
D.zero_grad()
D_loss.backward()
D_opt.step()
if step % n_critic == 0:
z = torch.randn(batch_size, n_noise).to(DEVICE)
z_outputs = D(G(z))
G_loss = criterion(z_outputs, D_labels)
G.zero_grad()
G_loss.backward()
G_opt.step()
if step % 500 == 0:
print('Epoch: {}/{}, Step: {}, D Loss: {}, G Loss: {}'.format(epoch, max_epoch, step, D_loss.item(), G_loss.item()))
if step % 1000 == 0:
G.eval()
img = get_sample_image(G, n_noise)
imsave('samples/{}_step{}.jpg'.format(MODEL_NAME, str(step).zfill(3)), img, cmap='gray')
G.train()
step += 1위 코드에서 GAN의 핵심적인 아이디어를 확인할 수 있습니다.
for idx, (images,_) in enumerate(data_loader) :
- idx 는 말 그대로 반복(iteration)을 나타내는 index 입니다.
- ' ~ enumerate(data_loader) ' : data_loader 에서 가져온 dataset 은 mini batch 단위로 나누어져 있는 상태입니다.
이 때, 이 dataset 은 MNIST image 인데, MNIST images 는 '이미지'+'라벨' 로 구성되어 있습니다.
- ' (images,_) ' : 따라서 data_loader 에 있는 MNIST images에서 'images'와 '나머지' = (라벨)를 분리(unpacking)합니다.
if step % n_critic == 0:
- 리뷰 파트에서는 자세하게 다루지 않았지만,
코드 정리를 할 때 n_critic = 1 의 의미에 대해서 설명 드렸었습니다.
- 'if step % n_critic == 0:' 은 step 이 n_critic 의 배수일 때만 조건문이 참이다.
라는 뜻입니다.
- 이 때, if 아래의 조건문은 Generator에 관한 조건문이네요.
만약에 n_critic = 5 라고 해봅시다. 'step%n_critic ==0 ' 은 step 이 0, 5, 10, 15 .. 일 때만 만족됩니다.
따라서 0, 5, 10 번 째 step 에서만 Generator 가 업데이트가 되겠죠.
" 따라서 D를 (n_critic)번 업데이트 한 후, G 를 한 번 업데이트 한다. "
라는 GAN 의 핵심적인 아이디어를 구현한 코드 입니다.
- 구현된 코드에서는 n_critic =1 이라고 설정되어 있으므로,
G 와 D 가 번갈아 가면서 업데이트 되겠네요.
( 이론적인 내용은 n_critic = 1 로 정의한 코드 부분에서 확인 )
loss function 설명
D_labels = torch.ones(batch_size, 1).to(DEVICE) # Discriminator Label to real
D_fakes = torch.zeros(batch_size, 1).to(DEVICE)
~
x = images.to(DEVICE)
x_outputs = D(x)
z = torch.randn(batch_size, n_noise).to(DEVICE)
z_outputs = D(G(z))
~
D_x_loss = criterion(x_outputs, D_labels)
D_z_loss = criterion(z_outputs, D_fakes)
~
D_loss = D_x_loss + D_z_loss
~
G_loss = criterion(z_outputs, D_labels)
- 논문 리뷰에서 GAN 의 loss function이 두 개의 항으로 이루어져 있었죠.
그리고 두 개의 항 모두에서 D 가 포함되어 있었고 ( [ log(D(x)) ] & [ 1-log(D(G(z))) ] )
두 번째 항에서만 G 가 포함되어 있었습니다. ( [ 1-log(D(G(z))) ] )
이 때, D_labels 은 1로 이루어진 행렬이고 D_fakes 는 0으로 이루어진 행렬이라는 것을 다시 한 번 상기시켜 봅시다.
1. D_x_loss 는 x_outputs와 D_labels 을 비교합니다.
x_outputs 는 D(x) = D(real image) 입니다.
따라서 D의 입장에서 생각해 보면, 이상적인 x_outputs, D(x) 은 1이 출력이 되면 좋겠죠?
따라서 D의 입장에서 생각해 보면, 이상적인 x_outputs(이상적인 경우 1) 과 D_labels(전부 1로 이루어짐) 을 비교하면 loss 가 0이 되겠죠.
2. D_z_loss 는 z_outputs 와 D_fakes 를 비교합니다.
z_outputs 은 D(fake image) = D(G(fake data)) = D(G(z)) 입니다.
따라서 D의 입장에서 생각해 보면, 이상적인 z_outputs, D(G(z)) 은 0이 출력이 되면 좋겠죠?
따라서 D의 입장에서 생각해 보면, 이상적인 z_outputs(이상적인 경우 0)과 D_fakes(전부 0로 이루어짐) 을 비교하면 loss 가 0이 되겠죠.
3. G_loss 는 z_outputs 와 D_labels 을 비교합니다.
z_outputs 은 D(fake image) = D(G(fake data)) = D(G(z)) 입니다.
따라서 G의 입장에서 생각해 보면, 이상적인 z_outputs, D(G(z)) 은 1이 출력이 되면 좋겠죠? ( ∵ D 를 속여야 하므로)
따라서 G의 입장에서 생각해 보면, 이상적인 z_outputs(이상적인 경우 1)과 D_labels(전부 1로 이루어짐) 을 비교하면 loss 가 0이 되겠죠.
# generation to image
G.eval()
imshow(get_sample_image(G, n_noise), cmap='gray')G와 D를 adversarial 하게 훈련시킨 이후부터는 사실 D가 잘 판별해내는지 마는지는 더 이상 궁금하지 않습니다.
훈련 이 후, 우리가 보고 싶은건 오로지 G가 진짜같은 가짜 이미지를 얼마나 잘 생성했는지가 궁금합니다.
G.eval() :
진짜 random noise 로 부터 MNIST 와 유사한 이미지를 생성할 수 있는지 확인하기 위해
G를 평가 모드로 설정합니다.
그리고 처음에 정의하였던 'get_sample_image' 를 통해 'G' 를 통과한 'n_noise' 가 어떻게 출력이 되는지
imshow 를 이용해 확인합니다.
'Vision > Machine Learning' 카테고리의 다른 글
| Image Inpainting for Irregular Holes Using Partial Convolutions (0) | 2023.06.28 |
|---|---|
| [ML] 초간단 ML History 1 (0) | 2023.06.23 |
| Context Encoder (0) | 2023.06.17 |
| SRCNN ( Super-Resolution CNN ) (0) | 2023.06.16 |
| AlexNet (0) | 2023.06.15 |

{kind=link}